Geometry is for Squares
(Note: this has nothing to do with geometry.)
God I love stats.
A lot of the time it seems like the visual representation of data is sacrificed for the actual numerical analyses—be they summary statistics, ANOVAs, factor analyses, whatever. We seem to overlook the importance of “pretty pictures” when it comes to interpreting our data.
This is bad.
One of the first statisticians to recognize this issue and bring it into the spotlight was Francis Anscombe, an Englishman working in the early 1900s. Anscombe was especially interested in regression—particularly in the idea of how outliers can have a nasty effect on an overall regression analysis.
In fact, Anscombe was so interested in the idea of outliers and of differently-shaped data in general, he created what is known today as Anscombe’s quartet.
No, it’s not a vocal quartet who sings about stats (note to self: make this happen). It is in fact a set of four different datasets, each with the same mean, the same variance, the same correlation between the x and y points, and the same regression line equation.
From Wiki:
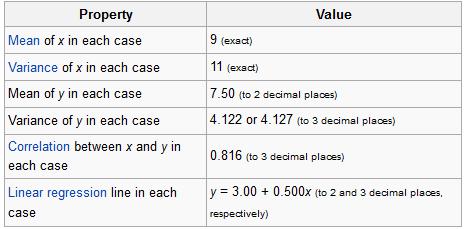
So what’s different between these datasets? Take a look at these plots:

See how nutso crazy different all those datasets look? They all have the same freaking means/variances/correlations/regression lines.
If this doesn’t emphasize the importance of graphing your data, I don’t know what does.
I mean seriously. What if your x and y variables were “amount of reinforced carbon used in the space shuttle heat shield” and “maximum temperature the heat shield can withstand,” respectively Plots 2 and 3 would mean TOTALLY DIFFERENT THINGS for the amount of carbon that would work best.
So yeah. Graph your data, you spazmeisters.
GOD I LOVE STATS.
Adventures in R: Creating a Pseudo-CDF Plot for Binary Data
(Alternate title: “Ha, I’m Dumb”)
(Alternate alternate title: “Skip This if Statistics Bore You”)
You may recall a few days ago during one of my Blog Stats blogs I mentioned the problem of creating a cumulative distribution function-type plot for binary data, which would show the cumulative number of times one of the two binary variables occurred over some duration of another variable.
Um, let’s go to the actual example, ‘cause that description sucked.
Let’s say I have two variables called Blogs and Images for a set of data for which N = 2193. The variable Blogs gives the blog number for each post, so it runs from 1 to 2193. The variable Images is a binary variable and is coded 0 if the blog in question contains no image(s) and 1 if the blog contains 1 or more images.
Simple enough, right?
So what I was trying to do was create an easy-to-interpret visual that would show the increase in the cumulative number of blogs containing images over time, where time was measured by the Blogs variable.
Not being ultra well-versed in the world of visually representing binary data, this was the best I could come up with in the heat of the analysis:

If you take a look at the y-axis, it becomes clear that due to the coding, the Images variable could only either equal 0 or 1. When it equaled 1, this plot drew a vertical black line at the spot on the x-axis that matched the corresponding Blogs variable. It’s not the worst graph (and if you scan it at the grocery store, you’ll probably end up with a bag of Fritos or something), but it’s not the easiest-to-interpret graph on the planet either, now is it?
What I was really looking for was some sort of cumulative distribution function (CDF) plot, but for binary data. I like how Wiki puts it: “Intuitively, [the CDF] is the “area so far” function of the probability distribution.” As you move right on the x-axis, the CDF curve lines up with the probability (given on the y-axis) that the variable, at that point on the x-axis, is less than or equal to the value indicated by the curve. Assuming your y-axis is set for probability (mine isn’t, but it’s still easy to interpret). This is all well and good for well-behaving ratio data, but what happens if I want to do such a plot for a dichotomously-coded variable?
There were two ways to go about this:
1) Be a spazz and write some R code to get it done, or
2) Be an anti-spazz and look up if anybody’s written some R code to get it done.
I originally wanted to do A, which I did, but B was actually a lot harder than it should have been.
Let’s look at A first. I wanted to plot the number of surveys containing images against time, measured by the Blogs variable. Since I coded blogs containing images as 1 and blogs not containing images as 0, all I needed to get R to do was spit out a list of the cumulative sum of the Images variable at each instance of the Blogs variable (so a total of 2193 sums). Then plot it.
R and I have a…history when it comes to me attempting to write “for” loops. But it finally worked this time. I’ll just give you that little segment, ‘cause the rest of the code’s for the plotting parameters and too long/bothersome to throw on here.
for (m in (1:length(ximage))){
newimage=ximage[1:m]
xnew=sum(newimage)
t=cbind(m,xnew)
points(t,type="h",pch="1")
}
ximage is the name of the vector containing the coded Images variable. So what this little “for” loop does is create a new variable (newimage) for every vector length between 1 and 2193 instances of the Images variable. Another new variable (xnew) calculated the sum of 1s in each newimage. t combines the Blogs number (1 through 2193) with the matching xnew. Finally, the points of t are plotted (on a pre-created blank plot).
So. Wanna see?

Woo!
So I actually figured this out on Wednesday, but I didn’t blog about it because I wanted to see if I could find a function that already does what I wanted. Why did it take an extra three days to find it? Because I couldn’t for the life of me figure out what that type of plot was called. It’s not a true CDF because it’s not a continuous variable we’re dealing with. But after obsessively searching (this is the reason for the alternate title—I should have known what this type of plot was called), I finally found a (very, very simple) function that makes what this is: a cumulative frequency graph (I know, I know, duh, right?).
So here’s the miniscule little bit of code needed to do what I did:
cumfreq=cumsum(ximage) plot(cumfreq, type="h")
The built-in function (it was even in the damn base package. SHAME, Claudia, SHAME!!) cumsum gives a vector of the sum at each instance of ximage; plotting that makes the exact same graph as my code (except I manually fancied up my axes in my code).

Cool, eh?
Maybe I’ll post my full code once I make it uncustomized to this particular problem.
Benford’s Law: The Project
Exploratory Data Analysis Project 3: Make a Pretty Graph in R (NOT as easy as it sounds)
Seriously, the code to make the graphs is longer than the code to extract the individual lists of digits from the random number vector.
Anyway.
The goal was to show a simple yet informative demonstration of Benford’s Law. This law states that with most types of data, the leading digit is a 1 almost one-third of the time, with that probability decreasing as the digit (from 1 to 9) increases. That is, rather than the probability of being a leading digit being equal for each number 1 through 9 the probabilities range from about 30% (for a 1) to about a 4% (for a 9).
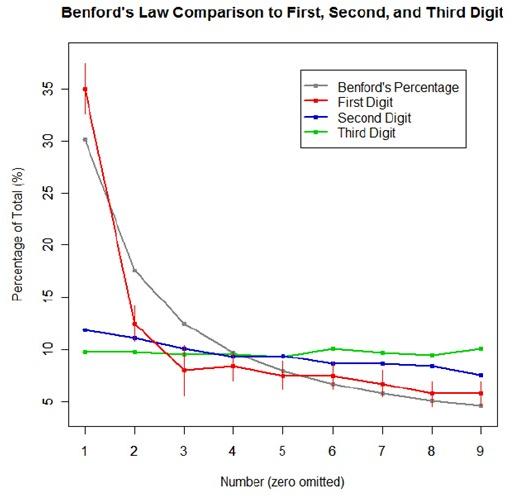
For the first graph, I wanted to show how quickly the law breaks down after the leading digit (that is, I wanted to see if the second and third digit distributions were more uniform). I took a set of 10,000 randomly generated numbers, took the first three digits of each number, and created a data set out of them. I then calculated the proportion of 1’s, 2’s, 3’s…9’s in each digit place and plotted them against Benford’s proposed proportions. Because it took me literally two hours to plot those stupid errors of estimate lines correctly (the vertical red ones), I just did them for the leading digit.
For the second graph, I took a data table from Wikipedia that listed the size of over 1,000 lakes in Minnesota (hooray for Wiki and their large data sets). I split the data so that I had only the first number of the size of the lakes, then calculated the proportion of each number. I left out the zeros for consistency’s sake. I did the same with the first 10,000 digits of pi, leaving out the zeros and counting each number as a single datum. I wanted to see, from the second graph, how Benford’s law applied to “real life” data and to a supposedly uniformly-distributed set of data (pi!).

Yes, this stuff is absolutely riveting to me. I had SO MUCH FUN doing this.

