Today’s Blog Post Brought to You By: Doomscrolling!
That’s like all I did today, haha.
Anyway.
Informative, but depressing.
I can see people being critical of the lack of numbers/values/scale, but like they say in the video, they’re trying to make it something that anyone can understand from a purely visual standpoint. It’s something to get a conversation started, and even if that starting point is, “well, how legitimate is this? There isn’t even a scale or any indication of how different the light red is from the darker red,” then that’s still getting people talking. “Sparking conversation” as they say in the vid.
(Also, they do offer a scaled version of each display; click the “bars with scale” display option for a given location).
Here’s Calgary:
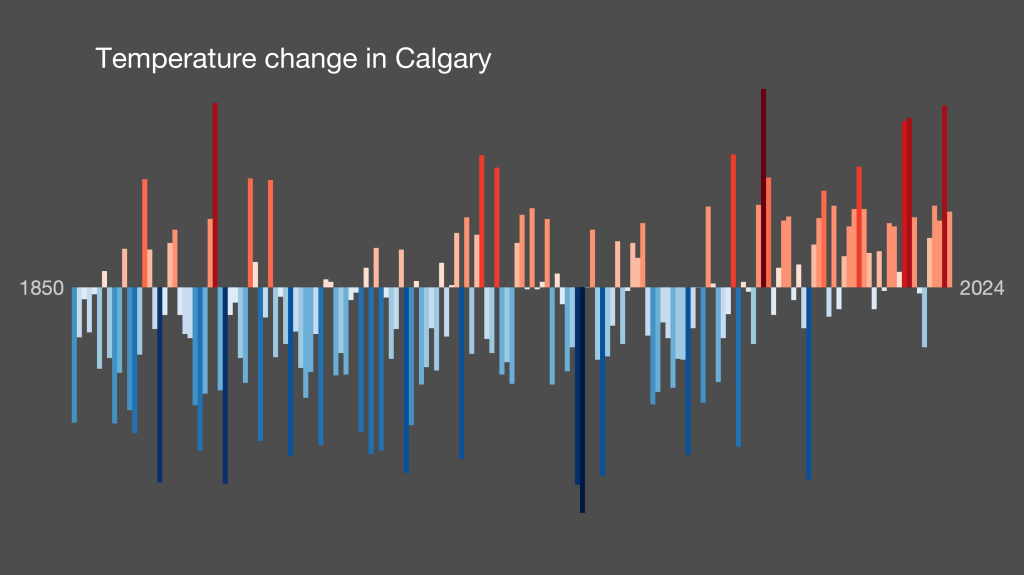
This is actually one of the least extreme ones. Look at Tucson:

Yikes.
OH MY GOD AAAAAAAAAAAAAAA
I have discovered the Bureau International des Poids et Mesures (BIPM) and I am IN LOVE
They have a section on the history of the SI.
A VIDEO on the SI.
SI PROMOTION MATERIAL SLFJSLAFJLGHALFK
Some people have heroin. I have the SI units.
TWSB: Hear Me Out
DID YOU KNOW: the loudest a sound can be (on earth) is 194 decibels?
By definition, something that is 0 dB is giving off a sound that is just detectable to the human ear. Softer sounds get negative dBs, louder sounds get positive dBs. A 10 dB increase corresponds to a doubling in loudness, meaning that, for example, something that is 30 dB is twice as loud as 20 dB and three times as loud as 10 dB.
So why is the upper limit the very specific loudness of 194 dB? Because sound is vibration. More specifically, it’s longitudinal waves. It’s like if you took a slightly stretched slinky, laid it out straight, and then rapidly pushed in and pulled back on one end of the slinky. The compressed metal spirals would move along the slinky’s body. That’s a longitudinal wave form.
For sound, this “compressed slinky” is compressed air (or whatever medium we’re in) and the compressed parts are parts of higher pressure (the expanded parts are parts of lower pressure).
Once we’re to the point that we’re hitting 194 dB, we’re at the threshold where this pressure wave switches to a shock wave. The energy is no longer moving through the air but is instead pushing the air outward. The “wave” becomes so extreme that the low pressure regions no longer have any molecules of air left in them to continue the push of the wave. All the molecules just move outward at once. It’s no longer technically sound as we define it in wave form. For example, the atomic bombs dropped on Hiroshima and Nagasaki were likely well over 200 dB and thus created shockwaves.
Also, if a shockwave is strong enough, it can freaking liquify you.
Isn’t that fascinating?
One of my old NaNoWriMo projects was about some guys trying to engineer the perfect sound that would resonate with the human body, but they get hooked on the euphoria they experience by this sound and continue to increase its intensity and volume and eventually kill themselves with it.
Y’know, just another one of my cheerful NaNo topics.
Anyway. Super cool, huh?
Another space thing, sorry not sorry
As I’ve said before (including in yesterdays’ blog, haha), I really like things that give us an idea of scale, especially when it’s a scale that’s really hard for humans to comprehend.
So here’s a model of the Solar System, where the coolest thing is the very clever inclusion of the closest star (apart from, of course, the sun):
Have I Posted This Before?
I don’t think I have. I had the intention to at some point, but I don’t think I ever did.
So here it is.
A simulation, obviously, but it gives you a sense of scale and space and I love stuff that gives us a good sense of scale and space, don’t you? It’s terrifying and beautiful and amazing all at the same time.
Happy Discovery Day, Uranus!
It was on this day in 1781 that William Herschel observed Uranus (the planet, you immature nerds) and initially recorded it as a comet. However, he compared it to a planet and other astronomers at the time were suspicious of the comet classification due to its orbit around the sun appearing to be nearly circular. It eventually became accepted as the seventh planet.
Uranus was also instrumental in discovering Neptune due to perturbations in its (Uranus’) orbit that could only be explained by the existence of another planet out there somewhere.
So that’s pretty cool.
MOON FAMILY!
So Saturn already held the record in the Solar System for the most moons at 146, but a set of 128 new satellites discovered by a team of astronomers back in 2023 have officially been classified as moons! Saturn now has 274 recognized moons, which is pretty insane. Most of these new moons are extremely small, but still.
Also, I’m just going to leave this here.
(Yes, it’s a SolarBalls episode; yes, I’m still wildly obsessed; yes, it’s relevant because SolarBalls Saturn would probably lose his mind over an additional 128 new moon names to memorize.)
Edit: in searching for a relevant article to this story, I found this NASA article from 1995 talking about the discovery of two to four new Saturnian moon candidates. Back then, the total confirmed number of moons was only 18. Pretty wild!
Look Up!
Are you as weirdly into clouds as I am? Then check out this lecture on basic cloud identification and naming!
We did a little bit of this when I took Geography 100 in Fall 2007, but it wasn’t as detailed and we actually didn’t look at example pictures for whatever reason.
Thanks, Mars!
Today, the Europa Clipper made its way past Mars on a gravity assist move to further support its eventual swing by Jupiter’s moon Europa!
(Tweet)
As I mentioned in a previous post about this, the Martian gravity assist did not boost Europa Clipper’s speed but reduced it instead. This is so that less propellant is needed, as the craft still has a long way to go to reach Jupiter.
In fact, it’s swinging back to earth first for another gravity assist before being flung out past the asteroid belt. This gravity assist will happen in December 2026; the craft will get to Jupiter in April 2030.
Pretty cool, huh?
Europa Clipper News!
The Europa Clipper launched about 4.5 months ago with the goal of eventually examining Jupiter’s moon Europa. On March 1, it will perform a gravity assist by flying by Mars.
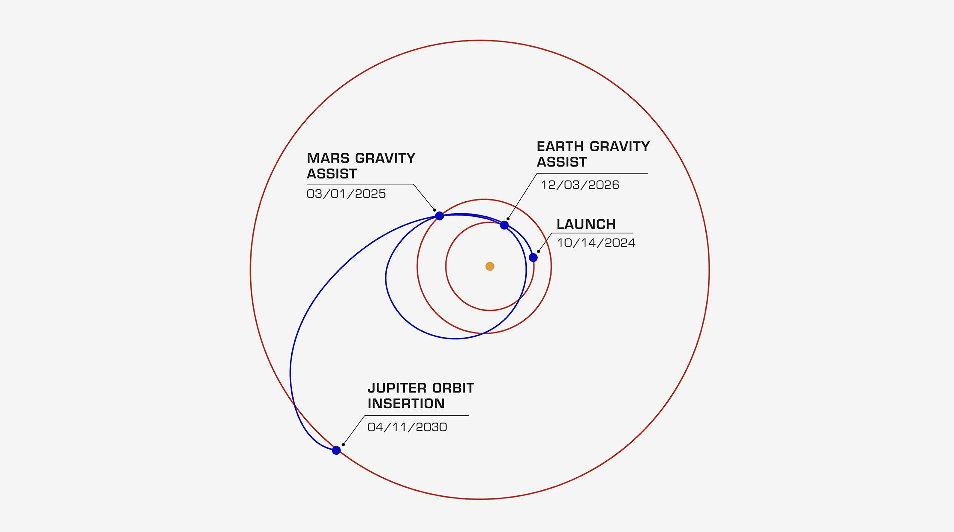
(Pic from here).
Unlike what you’d probably expect from something called a “gravity assist,” the Europa Clipper won’t be using Mars’ gravity to speed up but rather to slow down and reshape its orbit around the sun. This will set it up for a second gravity assist around the earth in late 2026 before it finally heads off to Jupiter.
Cool, huh?
I want to buy…
…a telescope!
We of course have a decent amount of light pollution in the city, but we can still see a good number of stars on a clear night. Makes me want to try out a nice telescope.
My mom used to have a telescope when I was a kid (was that on Borah? I can’t remember, haha), but I don’t think I ever got the hang of using it.
My biggest problem is that I’m actually exercising self-control over a purchase for once and I don’t feel like I know enough of the technical stuff to get the right telescope for what I want. It’s a big purchase and I’d want to make sure I’m getting what I need, so I’ll have to do more research on it.
Edit: Ooooh, nice site!
AAAAAA THIS IS COOL
So the sole flyby we’ve ever done of Uranus was by Voyager 2 in 1986. Of the many odd things about this planet, one extra strange thing observed by the spacecraft involved Uranus’ magnetic field. Namely, despite having radiation belts in its magnetosphere that were second only to Jupiter in intensity, there was no clear source of the energized particles or plasma that fed the belts.
However, new analyses of the 1986 data suggests that an unusual solar wind event may have been taking place during Voyager 2’s flyby of the planet, causing a change in its magnetosphere and temporarily stripping it of the plasma. According to scientists, these conditions occur about 4% of the time, and they just so happened to be taking place during the flyby. They suspect that Uranus’ magnetic field would have looked quite different had the flyby taken place even just a few days earlier.
Isn’t that wild?
I KNEW IT
Congenital anosmics breathe differently than smellers.
Turns out that people who smell take, as the article puts it, “exploratory sniffs.” The breathing rates between anosmics and smellers are the same, but smellers do like this little mini sniff-like inhale at the end of drawing a breath, and they do this several hundred times per hour.
During sleep or in a controlled odor-free room, the “extra inhalation” patterns even out between the two groups, but additional differences between the breathing patterns of the two groups were significant enough that researchers could tell if a person was a smeller or an anosmic with 85% accuracy just by looking at the breathing patterns.
It’d be interesting to expand upon this study by looking at acquired anosmics, too (this just compared congenital to smellers).
Puff Daddy: Planet Version
Thanks to my YouTube recommended list being like 90% astronomy-related now, I get to see stuff like this:
The idea of a planet having the density of Styrofoam is insane.
Good Luck, Europe Clipper!
And she’s off!
Not sure how things on earth will be going in 2030, but if we’re still somehow chugging along and not murdering each other for water, food, and other resources that we’ve destroyed due to climate change, the information this will send back will be so cool to see!
Scale
I think it’s really hard for humans to, in general, understand scale at either an extremely small level or an extremely large level. That’s why I’m always interested in things that attempt to help us understand such extremeness.
Such as this one! Here’s an attempt to give us an idea of the ridiculous size of the Solar System and the distances between the objects within it by traveling in “real time” at the speed of light from the sun outwards.
Also, slightly related, but I’m so glad that the little Solar System drawings are still on the Moscow side of the Chipman Trail. I’ve always loved those and their attempt at scale.
Did You Know…
That the area of the in which many water-related (and few land-related) constellations are located is called “The Sea” or “The Water?” And that it is suspected that this clustering of water-themed constellations exists because the sun passed through this part of the sky (at least where Ptolemy was naming constellations) during the rainy season?
Such constellations in “The Sea” include:
- Aquarius (the water-bearer)
- Capricorn (the sea-goat)
- Cetus (the whale)
- Delphinus (the dolphin)
- Eridanus (the river)
- Hydra (the water serpent)
- Pisces (the fishes)
Cool!
Houston, We Have a Big Bird
This is exactly the type of video that YouTube is for.
Sounds click-baity, but isn’t at all. Contains some weird facts about history plus info about a disaster. What more could you want?
(You know I love disasters.)
(Especially space disasters.)
Also, the comments are a mix of serious reactions from people who saw the explosion live and reactions of people speculating how much weirder it would have been if the recovery operation involved pulling a massacred Big Bird out of the wreckage. With some overlap between those two things, too.
Dottie
Interesting.
I always thought they were there to make the window defroster work better, haha.
Magnitude
Here is a wonderful demonstration of the exponential property of the Richter Scale.
I had no idea the scale technically went negative, so that’s pretty cool.
Solar
This is a wonderfully produced little documentary on our Solar System.
Uranus is such a weird planet, yo. It’s my favorite.
That is all.
ROCK YOU LIKE A HURRICANE…LAMP
This is incredibly interesting, yo.
I love this YouTube channel. So many different things explained so well!
Feelin’ Blue? Feelin’ Rare?
Here’s a cool article about why blue is such a rare color in nature. Basically, it boils down to how and why color is perceived. An object looks blue because that object is absorbing the red part of the visible spectrum. Red (and colors closer to it on the spectrum) has longer wavelengths compared to blue (and the colors closer to it on the spectrum), and thus is “low energy” compared to the other colors. For an object to appear blue, it must have molecules that can absorb very small amounts of energy. These types of molecules are difficult for plants to produce, and in animals, blue usually arises out of some sort of physical property of the animal that manipulates layers of light to produce only blue (like some butterfly wings or bird feathers).
The most interesting part of the article for me, though, was the discussion of how the word for blue was something that came much later in most languages compared to the words for, say, black, yellow, or red. It reminded me of a conversation we had in…I want to say Emotional Psychology class?…where we were talking about certain languages that didn’t/don’t have a different name for the colors blue and green – they are considered the same color, so they are named the same. I want to say Korean is one of these languages, but I could be wrong.
Anyway. Thought that was cool.
How fast can you throw Coldplay’s X&Y album?
(Because, you know, it’s an article about how fast sound can theoretically travel…and Coldplay has a song called “Speed of Sound”…and it’s on the X&Y album…I’ll stop now.)
ANYWAY.
So we all know about the speed of light, right? According to Einstein’s theory of special relativity, the fastest a wave can possibly travel is about 300,000 km/s: the speed of light. But what about sound? That is, is there an “upper limit” to the speed of a sound wave? Well, turns out there is.
In general, sound waves travel faster through solids faster than they do through gases or liquids. For example, sound travels through a diamond about 35 times faster than it does through air. That’s about as fast as sound can normally go. But how fast could it theoretically go?
Scientists at Queen Mary University and University of Cambridge theorized that the speed of sound should decrease with the mass of the atoms in a substance, meaning that sound should be fastest through solid hydrogen. They couldn’t actually physically test this, though, as hydrogen becomes a solid only under very, very high pressure (like +1 million atmospheres) that cannot be replicated on earth (yet). So they basically did a bunch of quantum mechanical calculations to see what the result should be and found that yes, the speed of sound in solid hydrogen is close to the theoretical limit of the speed of sound.
So that’s pretty cool!
UH OH
BOOM!
I think it’s so cool that so many of the stars that we can see may not even be there anymore. As the article states, since Betelgeuse is 642 light years from us, it could have done its supernova show that long ago and we would still be seeing it as “normal” in the sky.
That’s super wild.
Also, “The Armpit of Orion” would be a fantastic metal band name.

