Ch-Ch-Ch-Chernoff
Want to read about one of the weirdest types of data visualization? Then you want to read about Chernoff faces!
Chernoff faces are as weird as they sound. The idea is to represent different variables as features on a human face. For example, a person’s income could be represented by a Chernoff mouth, with a smile indicating higher incomes and a frown indicating lower incomes. Simultaneously, a person’s health could be represented by Chernoff eyes, with brighter and wider eyes corresponding to good health and tired, listless eyes corresponding to poor health. The more variables there are, the more facial components can be manipulated.
And if you think that sounds like it gets weird, it does:

(source)
The original motivation for Chernoff faces was that humans are basically primed to respond to and interpret faces and face-shaped things. Since we’re so good at interpreting faces, let’s turn data into faces so that we become good at interpreting the data, right?
Well, not really.
One of the main criticisms of Chernoff faces that is mentioned in the above article is that humans respond to faces “as a whole” rather than piece-by-piece. For example, when we look at two faces that differ only in the position of the eyebrows (maybe one has lowered eyebrows and the other has raised eyebrows), we don’t really think of the difference in that way. We think of the faces overall as having different expressions and thus different interpretations. We don’t focus on the eyebrows alone—we focus on the “whole package.”
While this is all well and good for actual faces, it actually makes interpreting changes in variables difficult to understand if those changes are represented by one or two changes on a Chernoff face.
Anyway. It’s actually a really interesting article discussing a really interesting and unique data presentation method. Give it a read!
An Exploration of Crossword Puzzles (or, “How to Give Yourself Carpal Tunnel Syndrome in One Hour”)
Intro
Today I’m going to talk about a data analysis that I’ve wanted to do for at least three years now but have just finally gotten around to implementing it.
EXCITED?!
(Don’t be, it’s pretty boring.)
Everybody knows what a crossword puzzle looks like, right? It’s a square grid of cells, and for each cell, it’s either blank, indicating that there will be a letter placed there at some point, or solid black, indicating no letter placement.
Riveting stuff so far!!!!!
Anyway, a few years back I got the idea that it would be interesting to examine a bunch of crossword puzzles and see what cells were more prone to be blacked out and what cells were more prone to being “letter” cells. So that’s what I finally got around to doing today!
Data and Data Collection
Due to not having a physical book of crossword puzzles at hand, I picked my sample of crosswords from Boatload Puzzles. Each puzzle I chose was 13 x 13 cells, and I decided on a sample size of n = 50 puzzles.
For each crossword puzzle, I created a 13 x 13 matrix of numbers. For any given cell, it was given the number 1 if it was a cell in which you could write a letter and the number 2* if it was a blacked out cell. I made an Excel sheet that matched the size/dimensions of the crossword puzzle and entered my data that way. I utilized the super-handy program Peek Through, which allowed me to actually overlay the Excel spreadsheet and see through it so I could type the numbers accurately. Screenshot:
Again, I did this for 50 crossword puzzles total, making a master 650 x 13 matrix of data. Considering I collected all the data in about an hour, my wrists were not happy.
Method and Analysis
To analyze the data, what I wanted to do was to create a single 13 x 13 matrix that would contain the “counts” for each cell. For example, for the first cell in the first column, this new matrix would display how many crosswords out of the 50 sampled for which this first cell was a cell in which you could write a letter. I recoded the data so that letter cells continued to be labeled with a 1, but blacked-out cells were labeled with a zero.
I wrote the following code in R to take my data, run it through a few loops, extract the individual cell counts across all 50 matrices, and store them as sums in the final 13 x 13 matrix.
x=read.table('clipboard', header = F)
#converts 2's into 0's for black spaces; leaves 1's alone
for (y in 1:650) {
for (z in 1:13){
if (x[y,z] == 2) {
x[y,z] = 0
}}}
attach(x) #new x with recoded 0's and 1's
n = (as.matrix(dim(x))[1,])/13 #gives number of puzzles in dataset
bigx = matrix(rep(NaN, 169), nrow = 13, ncol = 13) #big matrix for sums
hold=rep(NaN, n) #create blank "hold" vector
for (r in 1:13) {
for (k in 1:13) {
hold = rep(NaN, n) #clear "hold" from previous loop
for (i in 0:n) {
if (i < n) {
hold[i+1] = x[(i*13)+r,k] #every first entry in first row
}}
bigx[r,k] = sum(hold) #fill (r,k)th cell with # of white spaces
}}
Then I made a picture!
library(gplots)
ax = c(1:13) ay = c(13:1) par(pty = "s") image(x = 1:13, y = 1:13, z = bigx, col = colorpanel((50-25), "black", "white"), axes = FALSE, frame.plot = TRUE, main = "Letter vs. Non-Letter Cells in 50 13x13 Crossword Puzzles", xlab = "Column", ylab = "Row") axis(1, 1:13, labels = ax, las = 1) axis(2, 1:13, labels = ay, las = 2) box() #optional gridlines divs = seq(.5,13.5,by=1) abline(h=divs) abline(v=divs)
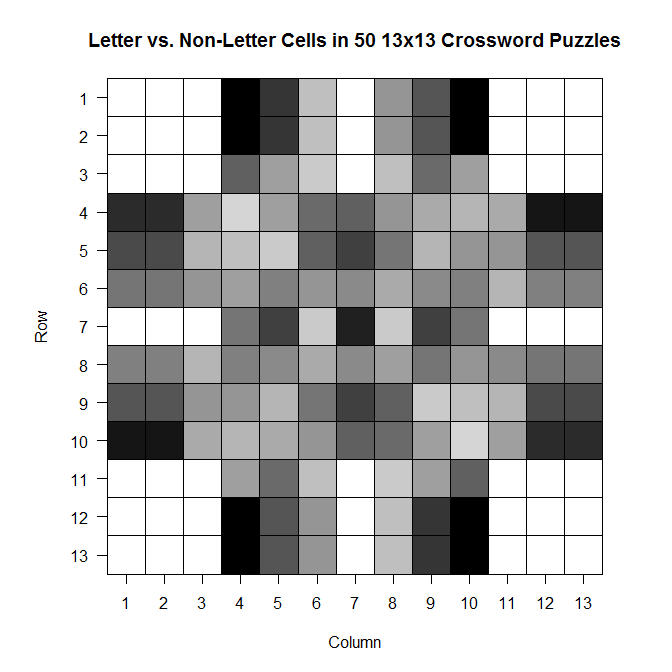
The darker a cell is, the more frequently it is a blacked out cell across those 50 sample crosswords; the lighter a cell is, the more frequently it is a cell in which you write a letter.
And while it’s not super appropriate here (since we’ve got discrete values, not continuous ones), the filled contour version is, in my opinion, much prettier:
library(gplots)
filled.contour(bigx, frame.plot = FALSE, plot.axes = {},
col = colorpanel((max(bigx)-min(bigx))*2, "black", "white"))

Note that the key goes from 25 to 50–those numbers represent the number of crosswords out of 50 for which a given cell was a cell that could be filled with a letter.
Comments
It’s so symmetric!! Actually, when I was testing the code to see if it was actually doing what I wanted it to be doing, I did so using a sample of only 10 crosswords. The symmetry was much less prominent then, which leads me to wonder that if I increased n, would we eventually get to the point where the plot would look perfectly symmetric?
Also: I think it would be interesting to do this for crosswords of different difficulty (all the ones on Boatload Puzzles were about the same difficulty, or at least weren’t labeled as different difficulties) or for crosswords from different sources. Maybe puzzles from the NYT have a different average layout than the puzzles from the Argonaut.
WOO!
*I chose 1 and 2 for convenience; I was doing most of this on my laptop and didn’t want to reach across from 1 to 0 when entering the data. As you see in the code, I just made it so the 2’s were changed to 0’s.
Geometry is for Squares
(Note: this has nothing to do with geometry.)
God I love stats.
A lot of the time it seems like the visual representation of data is sacrificed for the actual numerical analyses—be they summary statistics, ANOVAs, factor analyses, whatever. We seem to overlook the importance of “pretty pictures” when it comes to interpreting our data.
This is bad.
One of the first statisticians to recognize this issue and bring it into the spotlight was Francis Anscombe, an Englishman working in the early 1900s. Anscombe was especially interested in regression—particularly in the idea of how outliers can have a nasty effect on an overall regression analysis.
In fact, Anscombe was so interested in the idea of outliers and of differently-shaped data in general, he created what is known today as Anscombe’s quartet.
No, it’s not a vocal quartet who sings about stats (note to self: make this happen). It is in fact a set of four different datasets, each with the same mean, the same variance, the same correlation between the x and y points, and the same regression line equation.
From Wiki:
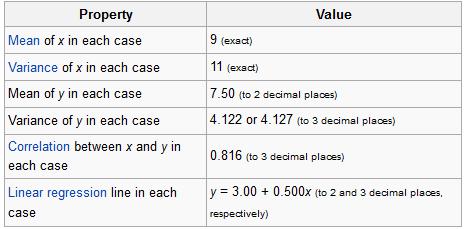
So what’s different between these datasets? Take a look at these plots:

See how nutso crazy different all those datasets look? They all have the same freaking means/variances/correlations/regression lines.
If this doesn’t emphasize the importance of graphing your data, I don’t know what does.
I mean seriously. What if your x and y variables were “amount of reinforced carbon used in the space shuttle heat shield” and “maximum temperature the heat shield can withstand,” respectively Plots 2 and 3 would mean TOTALLY DIFFERENT THINGS for the amount of carbon that would work best.
So yeah. Graph your data, you spazmeisters.
GOD I LOVE STATS.

