I hate this timeline
I go back and forth with humanity, man. I see people make art and sing and help each other and I’m like “awwww, humans are sweet.”
And then I see shit like this and I’m like “BURN US TO THE GROUND. ALL OF US RIGHT NOW.”
Both of these videos are so disgusting.
Suspiciously Good Summer Weather: Calgary Edition
I’m hesitant to blog about this because I don’t want to jinx it, but we’ve had the best summer weather this year. Especially this July. It’s usually obnoxiously hot/smoky/both during this month, but we’ve had tons of rain, lots of cloudy days, and, overall, very cool weather.
Heck, Tuesday was Calgary’s coldest July 22nd since records began in 1884. And July 21st? Same thing.
That’s wild.
The rain can be obnoxious (notice I’m posting book reviews in July; that does not happen unless I’m stuck on the treadmill), but this is so much better than the heat.
I’m trying to take advantage of the cool morning running weather, too.
MMM, TASTES LIKE NOSTALGIA
Remember this blog in which I reminisced about the cheesy garlic bread that I used to get at Pizza Hut when I was a kid/teen?
I forgot to follow that up with a review of this bread, since you can still get it up here in Canada (according to my mom, it’s no longer on the menu in the States – at least in Moscow).
My review? IT’S FREAKING GREAT

How good does that look? And it tastes exactly like I remember it.
So if you ever used to get this at Pizza Hut and you’re ever up in Canada, try it again? It’ll give you a big nostalgia hit.
Book Review: Three Men in a Boat (To Say Nothing of the Dog) (Jerome)
Have I read this before: Nope. This is a relatively recent addition to my book list.
Review: This was a really enjoyable read. Even though it was published in 1889, the humor in this one still lands. At first I didn’t really like the caveat stories because they interrupted the flow of the three men (and Montmorency, the dog) getting ready for their trip on the Thames, but they seemed like they integrated better as the story went on and thus they became more enjoyable. If you’re looking for a story that doesn’t take itself too seriously (which has been a really nice deviation from the typical books on my list), give this one a read. It’s not too long, either.
Favorite Part: Montmorency (the dog) chasing a big black tom cat and the resulting imagined conversation between them:
Montmorency does not lack pluck; but there was something about the look of that cat that might have chilled the heart of the boldest dog. He stopped abruptly, and looked back at Tom.
Neither spoke; but the conversation that one could imagine was clearly as follows:—
THE CAT: “Can I do anything for you?”
MONTMORENCY: “No—no, thanks.”
THE CAT: “Don’t you mind speaking, if you really want anything, you know.”
MONTMORENCY (backing down the High Street): “Oh, no—not at all—certainly—don’t you trouble. I—I am afraid I’ve made a mistake. I thought I knew you. Sorry I disturbed you.”
THE CAT: “Not at all—quite a pleasure. Sure you don’t want anything, now?”
MONTMORENCY (still backing): “Not at all, thanks—not at all—very kind of you. Good morning.”
THE CAT: “Good morning.”
…
To this day, if you say the word “Cats!” to Montmorency, he will visibly shrink and look up piteously at you, as if to say: “Please don’t.”
Rating: 7/10
Perspective
So as I’ve mentioned on here, I’m going through all my old blog posts one by one, recording information about them in an Excel spreadsheet, and fixing my “category” tags, as I have added a few more that seem appropriate additions to the 35 original categories I had (for example, I’ve added a “walking” category so that I can move all my walking-related posts out of the “health” category).
I’m currently in the middle of my Year 4, which corresponds to October 2009. What was I doing in October 2009? Starting grad school at UBC.
This made me realize something. My first round of undergrad took up only the first 3.5 years of my nearly 20 years of blogging. That is an incredibly short amount of time. In my head, I always think of that first round of undergrad as being a very significant portion of my life time-wise – probably because of all the stuff that happened during it – but at this stage of my life, it really was just a small blip.
Which is weird to think about.
Like, I’ve been living in Calgary for over 10 years now and that seems like a shorter amount of time than Undergrad Round I.
It’s weird how our brains frame things like that, isn’t it?
Do you have a period in your life that feels like it lasted a lot longer than it actually did?
Book Review: The Road (McCarthy)
Have I read this before: Nope.
Review: This was…okay. I was expecting to be a lot more shocked/disturbed by it based on what I knew about the novel, but it wasn’t nearly as shocking as I was expecting it to be. It was good, but some parts were a bit repetitive, especially in terms of how things were presented/described. Which may have been half the point, but still. At least it was a refreshing change in terms of voice and writing style compared to a lot of stuff on my list.
Favorite Part: I really liked the way the hope and relief was conveyed when they found the underground bunker full of supplies. It was nice to see the man and the boy finally get a bit of rest and relative safety, though I was worried that they’d be discovered the whole time they were down there.
Rating: 5/10
A Child’s Thoughts on Future Technology
Yo.
This is something I’ve mentioned in person to people, but I don’t think I’ve ever mentioned on here. It has to do with a very specific memory I have from when I was seven(-ish) and was living in Troy with my mom.
One evening, I remember looking at our wall-mounted corded phone. I thought about what phones would be in the far-off future (not sure what I considered the “far-off future” at that age, but whatev). I imagined that one day a phone would not only allow you to talk to the person on the other end, but would also allow you to see them. A video phone, if you will.
And that concept did come to fruition, right? We have FaceTime.
But that’s not the interesting thing to me about this prediction.
The image in my head that I had of this futuristic phone? It was still attached to the wall. It still had the corded handset.
My little 7-year-old mind could conceptualize a video phone, but it couldn’t come up with the additional advancements in phone technology. I couldn’t imagine a phone that you could hold in your hand and take with you; instead, I imagined the current iteration of phone tech with a new shiny video screen in it. It was this weird meld of new tech and old.
I’ve just always thought that was interesting.
Anyway.
*Brian Regan voice* “ARE THESE MY GLASSES??!?!?!?!”
I got my new fancy-shmancy “your eyes are wonky so here are some prisms” glasses!
I guess it’s kind of dumb to blog about these today because I’ll probably take a while to get used to them, but I’ve got them on and am ready for the magic.
Update 1: my depth perception is whacked out. At least for far away things.
Update 2: after using my computer and doing stuff like my French lessons on my phone, I am noticing that the text isn’t jittering around like it used to. Which is nice.
Update 3: I haven’t had a headache (except for a weather headache due to major pressure changes) since I’ve started wearing these.
Update 4: I read in the car for FIVE MINUTES and only got slightly nauseous. I can usually only stand a few seconds before I want to puke.
Update 5: depth perception is still a little wonky, but I think it’s getting better.
Book Review: Pnin (Nabokov)
Have I read this before: Nope. But apparently I’m in a Nabokov mood right now, so let’s go.
Review: Pnin is like academia personified. He’s strange, he’s kind of odd-looking, he’s a bit socially awkward but also socially graceful in certain situations, he makes little absent-minded mistakes…he’s an old prof, basically. I like how we get an idea of who he is through these little snippets of incidents throughout his life.
My biggest issue was not knowing how “Pnin” was supposed to be pronounced, but then I found the most Nabokov way of explaining how it should be pronounced:
“In one of his essays Nabokov said it should be pronounced like “Up, Nina!” without the first and last letters.”
Favorite Part: Story-wise? Pnin not being sure if there is one professor with a certain last name or two different profs who look similar and have similar names. So he invites one of them to his housewarming party, calling him one of the names, and then that prof, upon leaving, is super confused because he’s a totally different dude than the two Pnin is confusing, haha.
Writing-wise? That good old Nabokov sentence that connects the very physical to the very cosmic:
“With the help of the janitor he [Pnin] screwed onto the side of the desk a pencil sharpener—that highly satisfying, highly philosophical implement that goes ticonderoga-ticon-deroga, feeding on the yellow finish and sweet wood, and ends up in a kind of soundlessly spinning ethereal void as we all must.”
(like ALL of Lolita was written like this; hence why it’s one of my favorites.)
Rating: 6/10
A Hypothetical:
What if we taught the ABC’s in the order of the QWERTY layout?
*to alphabet song melody*
Q, W, E, R, T, Y, U
I, O, P, A, S, D, F
G, H, J
K, L, Z
X, C, V
B, N, M
Now I know my QWE’s
This is what technology’s done to me!
Is it ART or is it TRASH?
It’s TRASH!

It’s a flower, but it doesn’t even look like one.
In my defense, though, neither does the actual flower itself:

I have no idea what kind of flower this thing is, but it gave me a good chance to try out my new metallic watercolor set. It’s hard to tell in the picture of the painting, though.
Book Review: Pale Fire (Nabokov)
Have I read this before: Nope. This is only my second Nabokov, which is surprising given how much I LOVE his writing style.
Review: I’ve always enjoyed books with an unconventional structure. This definitely has that. It starts with a four-canto poem by fictional poet John Shade, then is followed by a long commentary by his (fictional) neighbor and colleague, Charles Kinbote. He examines the poem nearly line-by-line, interjecting commentary in the form of three main stories: his personal interactions with and knowledge of Shade, a story about the deposed king of Zembla, and Gradus, an assassin from Zembla sent to kill the old king.
Favorite Part: Y’all know I like it when everything builds beautifully to a final point in a story. So few stories pull this off very well, in my opinion, but this one does it nicely. Also, because it’s Nabokov, I have to mention the way he explains how Kinbote took all the index cards on which Shade had written the lines of his poems and hid them on his person to keep them safe:
Some of my readers may laugh when they learn that I fussily removed it from my black valise to an empty steel box in my landlord’s study, and a few hours later took the manuscript out again, and for several days wore it, as it were, having distributed the ninety-two index cards about my person, twenty in the right-hand pocket of my coat, as many in the left-hand one, a batch of forty against my right nipple and the twelve precious ones with variants in my innermost left-breast pocket. I blessed my royal stars for having taught myself wife work, for I now sewed up all four pockets. Thus with cautious steps, among deceived enemies, I circulated, plated with poetry, armored with rhymes, stout with another man’s song, stiff with cardboard, bullet-proof at long last.
I LIKE THE WAY HE WRITES I’M SORRY.
Rating: 5/10
D-D-D-DISTANCE
Here’s my Sunday-through-Sunday distance (in miles) this week:
- Sunday: 31.35 running, 4.59 walking
- Monday: 20.14 walking
- Tuesday: 20.05 running, 4.93 walking
- Wednesday: 20.17 walking
- Thursday: 26.24 running, 4.17 walking
- Friday: 20.07 walking
- Saturday: 10.1 walking (off day)
- Today: 26.34 running, 4.28 walking
Total: 192.43
Somebody has to do it.*
*Absolutely nobody has to do it; I’m just insane.
HAHAHA WHAT THE HELL IS GOING ON
Look at my daily blog views, friends:

EXCUSE ME??
Almost SIX THOUSAND views in one day?
For someone who usually gets like 25 per day max (except for recently with that guy from Columbus), that’s insane. And unprecedented. And weird.
I figured these views were from Columbus Guy, but nope:

We’re in Germany now, apparently.
So yeah, yet another weird blog viewing pattern that’s new and strange and unexplainable.
Interesting.
Edit: it went back down to normal after today and hasn’t spiked again since, so…
What is THIS
And why does it look super fun?
This would actually be really cool way to analyze my running gait and such. Calgary’s drone laws for small ones (< 250 grams) are basically “don’t fly it at the airport or into the blades of the medi-helicopter and you’re good” so that would be fine. I’d just want to do it somewhere where I wouldn’t be bothering anyone else.
It would also, y’know, just be fun to play with, haha.
IT IS SO TEMPTING AAAAA
*picks up blog post and throws it into the stratosphere*
BEGONE, USELESS DRIVEL!
(I’m really hyper, sorry)
1. Of the five weekdays, which is the easiest to get through?
I’ve always liked Tuesdays. It’s a running day, so it’s off to a good start, and it’s early enough in the week that you still feel like you have time to accomplish stuff if you’re super busy. The only bad thing about Tuesdays is that they precede Wednesdays. Wednesday is probably my least favorite weekday.
2. Which of the five little piggies is the most bizarrely characterized?
I don’t know if it’s necessarily a bizarre characterization, but the one that went “wee, wee, wee” all the way home is the most intriguing. Where’s he going home from? The market? Did he escape? WHY YOU SQUEALING, BRO, THEY’LL FIND YOU AND CATCH YOU
3. Of fire, earth, metal, water, and wood, from which do you draw your power?WHERE IS AIR I’M AN AIR SIGN GODDAMMIT
Well, of the elements listed, I’m going with fire. Mainly because 1) it’s the element associated with my Chinese zodiac year of birth, and 2) FIRE = RAGE
4. Haribo Gummy Bears come in five flavors: pineapple (white), strawberry (green), raspberry (red), lemon (yellow) and orange (orange). Which is your favorite?
They all taste the same to me.
5. Which of the five basic tastes (sweetness, sourness, bitterness, saltiness, and savoriness) best describes your personality?
I’d say savory. Do I exist as a separate taste? Or am I an amalgamation of salty and sweet? Am I overwhelming? DO YOU WANT ME????
This is beautiful.
I’m not a poetry person, but this is striking.
I’ve never heard any other poetry from Andrea Gibson, but this one will stick with me.
Edit from July 14th: I just found out that Andrea died today. Rest in peace.
I cannot express to y’all…
…how much I LOVE HIM

There was one bag of the Cheeky Cheddar Munchies at Fresh Co so I bought it in order to have a physical version of this cheesy bro in my office for all eternity. Here is the front of said bag:

Edit: THERE IS A WEBSITE
Edit 2: THERE IS A .GIF

The others are cute, but Cheese Man is untouchable.
(Also, I did July’s 50k today because I figure the rest of the month is just going to get hotter.)
(Super exciting.)
AAAAAAAAEAAAAAEAEA
Fun activity (for me, not for you): find an old survey as you’re working on your blog archives and see how many of your answers have changed. Old answers that are no longer relevant are crossed out. Old answers that still apply are…well, just there, haha.
READY GO
1. What is your middle name?
Marie
2. How big is your bed?
Twin I think it’s a queen?
3. What are you listening to right now?
The NEDM song. Some obnoxious magpie outside.
4. What are the last 4 digits in your cellphone number?
-5120 -2292.
5. What was the last thing you did?
Taped cellophane over my light. Haha. Walked home from SaveOn.
6. Last person who drove you somewhere?
My mom Nate.
7. How is the weather right now?
It’s cold ‘cause it’s dark, but it was nice and warm today Hot, but not too hot. That’s coming later this week.
8. Who was the last person you talked to on the phone?
My mom
10. Favorite type of Food?
Anything carbs, haha.
11. Do you want children? How many?
NO!
12. What is a strange fact about you?
Can’t smell
13. Ever get so drunk you don’t remember the entire night?
Nope
14. Hair color?
Black
15. Eye color?
Hazel
16. Do you wear eye contacts?
Nope
17. Favorite holiday?
Christmas
18. Favorite Season?
Summer I don’t think I have one anymore.
19. Have you ever cried over a girl/boy?
Unfortunately
20. Last Movie you watched?
Don’t remember
21. Something you can’t wait for?
Grad school Death.
22. Do you chew ice?
Ew
23. McDonalds or Burger King?
McDonalds
24. Would you like some beer? milk? bologna?
Milk sounds good right now Nah.
25. Do you know what the snack that smiles back is?
GOLDFISH!
26. Are you feeling extra happy today?
Pfft NEVER
27. Good or evil?
Good
28. Favorite disney movie?
Toy Story, bitches!
29. What book are you reading?
Hawking’s Brief History of Time Nabokov’s Pale Fire.
30. Piercings?
Earlobes and an industrial in my right ear Two in my right lobe, one in my left, the industrial healed over.
31. Favorite Movie?
Apollo 13 is pretty awesome
32. Favorite MLB Team?
The Braves, just ‘cause of my mom METS!
33. What were you doing before this?
Just sitting here Crying.
34. Any pets?
Annabelle, Romeo, both cats Pepper, a cat.
35. sun tan or tanning bed?
Neither
36. Who’s your favorite anchorman?
Um…
37. Luke or Owen Wilson?
Not a big fan of either.
38. Favorite Flower?
Oregon Grapes
39. What movie do you look forward to seeing?
Watchmen! Fantastic Four.
40. Have you ever loved someone?
Yes
41. Who would you like to see right now?
Aaron! Leibniz.
42. Last time you cried?
Couple nights ago A few minutes ago.
43. Last game you played?
Gears of War 2 Mahjongg.
44. Do you like to travel by plane?
Yup NO I HATE IT NOW.
45. Right-handed or Left-handed?
Right
46. If you could go to any place right now where would you go?
Antarctica!
47. Are you missing someone?
Nah My mom.
48. Ever notice how songs you loved when you were little, are even more dirty now?
Hahahaha, Barbie Girl
49. Do you have a tattoo?
Unfortunately not
50. Do you still watch cartoons on Saturday morning?
Don’t have a TV Have a TV, but nope.
51. Are you hiding something from someone?
Yeah Eh.
52. Are you 18?
Nope, 21 Hahahaha. Haha. Nope.
53. What is the wallpaper on your cellphone?
I think it’s a bunch of clocks LEIBNIZ.
54. Did you get enough sleep last night?
For me, yes
55. First thing you thought about this morning?
Do I have to do this again? Really?
57. Grilled or fried?
Depends on what we’re talking about
58. What’s your favorite SNL cast member?
The only one I know is (was?) Will Farrell
59. When’s the last time you saw your best friend(s)?
Couple days ago Don’t have a best friend.
60. Are you afraid of the dark?
Nope
61. When was your last road trip?
Missoula! Best time ever Our trip down the West Coast. 2015.
63. First thing you will buy if given 50 thousand dollars?
A ticket to Antarctica Something for my mom. Whatever she wants.
64. Favorite song(s)?
Sleepyhead!! Sleepyhead is still up there, but Call on Me has surpassed it.
65. What are you afraid of?
Failure
66. Are you a giver or a taker?
I like to think I’m a giver
67. What do people call you for short?
Aaron calls me Claudsie Nothing.
68. What is your dads middle name?
Louis
69. What’s your mothers middle name?
Ann
71. Favorite commercial?
No idea “AARON BURR!” If you know, you know.
72. Whos your cell phone provider?
AT&T? Freedom.
74. Favorite color?
Orange!
75. What are the things you’ll always bring with you?
My wallet…something to write on/write with…that’s about it My USB backups, haha.
76. What did you want to be when you were a kid?
A glaciologist
77. What do you usually do when the clock turns 7am
Get angry at my alarm I’m usually out running or walking, at least in the summer.
78. The color of your bed sheets?
Tye-dye White-ish?
79. Who do you want to meet?
LEIBNIZ!
80. if you could sleep with anyone, who would it be?
LEIBNIZ!
Oh look, it’s a bunch of stuff nobody cares about!
THREE THINGS! Because lists are my jam, yo.
Item 1: I watched this video on Holt’s The Planets a while ago but was reminded of it again the other day when my mom and I were talking about…one of the movements? I can’t remember. Something about The Planets. Anyway.
Also, I’m an idiot. I always wondered why the movements were in the order they were (Mars is first and Mercury is third), but it makes sense now after watching this: he did it based on the order of the zodiac signs and their ruling planets instead of the order from the sun (ignoring, of course, the signs ruled by the moon and the sun and bringing in the modern rulers of Aquarius and Pisces – Uranus and Neptune, respectively).
Item 2: It’s the Fourth of July today, so this video must be rewatched, as per tradition:
Praise Reekris.
Item 3: It’s the Fourth of July today, so Twitter is rife with related tweets, such as this one:
DONE!
Claudia versus…Eyesight? I Guess?
So it turns out my EYES ARE WONKY.
Story time:
Nate and I went to the eye doctor today because it’s been like three years since we last went and he needs new frames. I figured I had no change in my prescription because last time the change was miniscule (my eyesight actually improved (??) but there was not enough of a change to warrant a new prescription) but I went anyway just because.
They do the eye exam and, as expected, no change at all. Then the eye doctor asks me two questions:
“Do you frequently get headaches?”
“Do you experience motion sickness?”
My answer to both of those questions was yes. I get frequent low-level headaches (which I’ve always assumed was just due to the wacky weather here) and I have very bad motion sickness, especially when trying to read in the car.
So he goes “interesting” and I think what do you mean ‘interesting????’ and he takes me into a different room to conduct further tests.
The “further tests” involve wearing a VR headset and having to focus on a little yellow dot while a bunch of other stuff was going on in the VR world. After the test was done they show me through the VR headset that my eyes don’t freaking point in the same direction and it messes with my focus (apparently I was very close to the upper threshold of misalignment that the test could measure, so that’s great). I’m focusing beyond what I need to focus on, especially when I’m looking at something up close. This causes double vision and consequently makes my brain continuously compensate for said double vision. This causes the headaches and the motion sickness, among other things.
So the eye doctor said that they have this thing called Neurolens, which is some sort of progressive prism lens that’s really supposed to help with this. They’re expensive, but he said that he’s had quite a few patients who tried them out and not one has asked for a refund after the 30-day trial.
I did some reading about them and it sounds like a lot of people really do benefit from them.
So I’m going to give them a try. It’d be nice not to have near-daily headaches and to be able to read in the car for more than 30 seconds before feeling nauseous.
We’ll see! I’ll let y’all know, even though I’m sure no one cares.
Interloper, IDENTIFY YOURSELF!
So…I noticed this happening with Eigenblogger:

And I was like “what is this unprecedented nonsense?” and looked at the individual post stats. Turns out it’s not XTREME POPULARITY for my blog as a whole but rather XTREME POPULARITY for this specific post:

Which is actually not even a legit blog post. It’s one of the pages you can click on in the list of pages at the top of my blog.
There’s nothing really even there…just links to actual blog posts pertaining to my Decade of Music Project.
The weirder thing? None of those five linked posts have many (if any) visits. Even the link to download the list of songs has only a single click in the past 30 days.
So…that’s odd.
Edit: and the vast majority of these visits are all coming from one place: Columbus, OH.
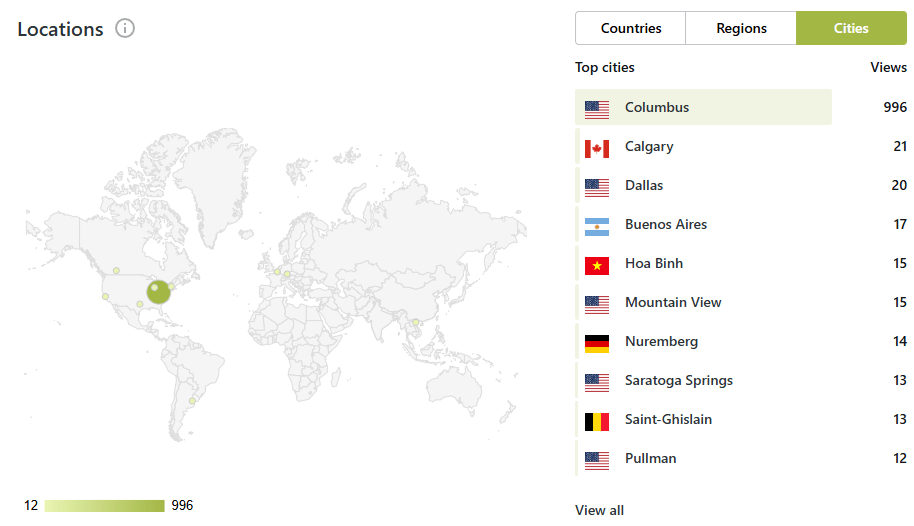
Interesting.
What you up to, Columbus Dude?
Leibniz Day 2025
It’s LEIBNIZ DAY, YOU NERDS!
Enjoy our modern world; much of it exists because of calculus. And philosophy. And a lot of other things he had a hand in (like binary!).
Have one of Eddie Woo’s fantastic videos, this time on Leibniz’ derivative notation:

