Correlation and Independence for Multivariate Normal Distributions
OOOOH, thisiscoolthisiscoolthisiscool.
So today in my multivariate class we learned that two sets of variables are independent if and only if they are uncorrelated—but only if the variables come from a bivariate (or higher multivariate dimension) normal distribution. In general, correlation is not enough for independence.
ELABORATION!
Let X be defined as:
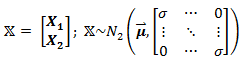
meaning that it is a matrix containing two sets of variables, X1 and X2, and has a bivariate normal distribution. In this case, X1 and X2 are independent, since they are uncorrelated (cov(X1, X2)=cor(X1,X2) = 0, as seen in the off-diagonals of the covariance matrix).
But what happens if X does not have a bivariate distribution? Now let Z ~ N(0,1) (that is, Z follows a standard normal distribution) and define X as:

So before we even do anything, it’s clear that X1 and X2 are dependent, since we can perfectly predict X2 by knowing X1 or vice versa. However, they are uncorrelated:

(The expected value of Z3 is zero, since Z is normal and the third moment, Z3, is skew.)
So why does zero correlation not imply independence, as in the first example? Because X2 is not normally distributed (a squared standard normal variable actually follows the chi-square distribution), and thus X is not bivariate normal!
Sorry, I thought that was cool.
The question is, “why DIDN’T the chicken cross the road?
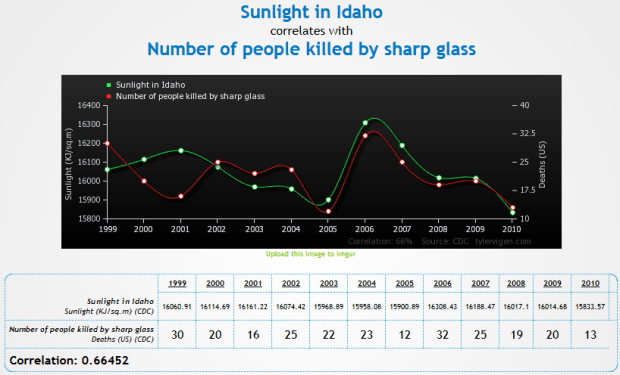
So I just found the greatest freaking website to demonstrate that correlation != causation.
Check it out.
Some of my favorites:
- http://www.tylervigen.com/view_correlation?id=7
- http://www.tylervigen.com/view_correlation?id=3857 (Look at how freaking strong that correlation is, holy hell)
- http://www.tylervigen.com/view_correlation?id=1273
- http://www.tylervigen.com/view_correlation?id=36
You can also discover your own:
Artz n’ Letterz
So this is something I noticed a long time ago, but going through my playlists in iTunes this afternoon made the observation come to the forefront of my mind: when I sort my “Top Favorites” playlist by artist, I notice that a large amount of the songs (68%) are by artists whose names begin with a letter from the first half of the alphabet (A – M). When I sort my entire music library in this manner, I find the same proportion (okay, 67%…it’s pretty damn close). And you know what’s more interesting? If I sort by the TITLE of the song, I get the same proportion again! OOH, OOH, and sorting my freaking book list gives the same 67% as the music.
I find this quite fascinating. Has anyone else ever noticed this type of pattern in any of their things? It’s interesting to me that this 2:1 ratio keeps coming up. This requires exploration.
Hypothesis: this 2:1 ratio occurs because the first half of the alphabet contain more letters that appear more often as the first letters in English words.
Method: utilizing letterfrequency.org, I found the list of the frequencies of the most common letters appearing as the 1st letter in English words*. I used this list as a ranking and, using a point-biserial correlation, correlated this ranking with a dichotomized list of the letters, in which letters in the first half of the alphabet were assigned a value of “0” and those in the second half of the alphabet were assigned a value of “1.”
Results: here are the two values being correlated alongside their respective letters:

Where the “X” column is ranking by the frequency of appearance as the first letter of a word and the “Y” column is a dichotomized ranking by alphabetical order. Point-biserial correlation necessary because one of the variables is dichotomous. So what were the results of the correlation? rpb = .20, p = .163.
Conclusion: well, the correlation isn’t statistically significant (p < .05) by a long shot, but I’ll interpret it anyway. A positive correlation in this case means that letters with the larger dichotomy value (in this case, those coded “1”) tend to also be those same letters with a “worse” (or higher-value) coding when ranked by frequency as the first letter in English words. So in plain English: there is a positive correlation between letters appearing in the second half of the alphabet and their infrequency as their appearance as the first letter in English words. In other words, letters appearing in the first half of the alphabet are more likely to appear as the first letter in English words. Not statistically more likely, but more likely.
Meh. Would have been cooler if the correlation were significant, but what are you going to do? Data are data.
*Q, V, X, and Z were not listed in the ranking, but given the letters, I assume that they were so infrequent as first letters that they were all at the “bottom.” Therefore, that is where I put them.
Scrabble Letter Values and the QWERTY Keyboard
Hello everyone and welcome to another edition of “Claudia analyzes crap for no good reason.”
Today’s topic is the relationship between the values of the letters in Scrabble and the frequency of use of the keys on the QWERTY layout keyboard.
This analysis took three main stages:
- Plot the letters of the keyboard by their values in Scrabble.
- Plot the letters of the keyboard by their frequency of use in a semi-long document (~50 pages).
- Compute the correlation between the two and see how strongly they’re related.
Step 1
There are 7 categories of letter scores in Scrabble: 1-, 2-, 3-, 4-, 5-, 8-, and 10-point letters. The first thing I decided to do was create gradient to overlay atop a QWERTY and see what the general pattern is. Here is said overlay:

Makes sense. K and J are a little wonky, but that might just be because the fingers on the right hand are meant to be skipping around to all the other more commonly-used letters placed around them. This was the easiest part of the analysis (except for making that stupid gradient; it took a few tries to get the colors at just the right differences for it to be readable but not too varying).
Step 2
I found a 50 or so page Word document of mine that wasn’t on anything specific and broke it down by letter. I put it into Wordle and got this lovely size-based comparison of use:

I then used Wordle’s “word frequency” counter to get the number of times each letter was used. I then ranked the letters by frequency of use.
I took this ranking and compared it to the category breakdown used in Scrabble—that is, since there are 10 letters that are given 1 point each, I took the 10 most frequently used letters in my document and assigned them to group 1, the group that gets a point each. There are 2 letters in Scrabble that get two points each; I took the 11th and 12th most frequently used letters from the document and put them into group 2. I did this for all the letters, down until group 7, the letters that get 10 points each.
So at this point I had a ranking of the frequency of use of letters in an average word document in the same metric as the Scrabble letter breakdown. I made a similar graph overlaying a QWERTY with this data:

Pretty similar to the Scrabble categories, eh? You still get that wonky J thing, too.
Side-by-side comparison:


Step 3
Now comes the fun part! I had two different ways of calculating a correlation.
The first way was the category to category comparison, which would require the use of the Spearman correlation coefficient (used for rank data). Essentially, this correlation would measure how often a letter was placed in the same group (e.g., group 1, group 4) for both the Scrabble ranking and the real data ranking. The Spearman correlation returned was 0.89. Pretty freaking high.
I could also compare the Scrabble categories against the raw frequency data, which would require the use of the polyserial correlation. Since the frequency decreases as the category number increases (group 1 has the highest frequencies, group 10 has the lowest), we would expect some sort of negative correlation. The polyserial correlation returned was -.92. Even higher than the Spearman.
So what can we conclude from this insanity? Basically that there’s a pretty strong correlation between how Scrabble decided to value the letters and the actual frequency of letter use in a regular document. Which is kind of a “duh,” but I like to show it using pretty pictures and stats.
WOO!
Today’s song: Sprawl II (Mountains Beyond Mountains) by Arcade Fire
Mmm, fresh data!
Hey ladies and gents. NEW BLOG LAYOUT! Do you like it? Please say yes.
Anyway.
So this is some data I collected in my junior year of high school. I asked 100 high schoolers a series of questions out of Keirsey’s Please Understand Me, a book about the 16 temperaments (you know, like the ISFPs or the ENTJs, etc.). When I “analyzed” this for my psych class back then, I didn’t really know any stats at all aside from “I can graph this stuff in Excel!” (which doesn’t even count), so I decided to explore it a little more. I wanted to see if there were any correlations between gender and any of the four preference scales.
The phi coefficient was computed between all pairs (this coefficient is the most appropriate correlation to compute between two dichotomous variables). Here is the correlation matrix:

First, it’s important to note how things were coded.
Males = 1, Females = 0
Extraversion = 1, Introversion = 0
Sensing = 1, Intuiting = 0
Feeling = 1, Thinking = 0
Perceiving = 1, Judging = 0
So what does all this mean? Well, pretty much nothing, statistically-speaking. The only two significant correlations were between gender and Perceiving/Judging and Sensing/Intuiting and Perceiving/Judging. From the coding, the first significant correlation means that in the sample, there’s a tendency for males to score higher on Perceiving than Judging, and for females to score higher on Judging. The second significant correlation means that in the sample, there’s a tendency for those who score high on Feeling tend to score high on Perceiving, and a tendency for those to score high on Thinking to score high on Judging.
The rest of the correlations were non-significant, but they’re still interesting to look at. There’s a positive correlation between being female and scoring high on Extraversion, There’s a correlation between being male and scoring high on Feeling, and there’s a very, very weak correlation between Feeling/Thinking and Extraversion/Introversion.
Woo stats! Take the test, too, it’s pretty cool.
Today’s song: Beautiful Life by Ace of Base
Correlation vs. covariance: they’re not the same, get it right
Blogger’s note: this is what Teddy Grahams do to me. Keep them away from me.
OKAY PEOPLE…another stats-related blog for y’all. Consider this nice little data set:

Isn’t it pretty? Let’s check out the covariance and correlation:
cov(x, y) = 7.3
cor(x, y) = 0.8706532
Now obviously that one point kind of hanging out there is an outlier, right? So let’s take it out:

Quick, before I do anything else—what do you think will happen to the correlation? What do you think will happen to the covariance?
This was a question for our regression practice midterm, but I heard someone today talking about covariance and correlation and they were completely WRONG…hence this blog. So I remember when I first got this question, I at first thought that both correlation and covariance should increase, but then that seemed like it wouldn’t make sense.
How do we tell?
Equation time!
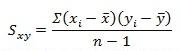
This is the equation for covariance. As you can see, in the numerator is the sum of the product of all the differences between all the X values and the mean of the X and the differences between the Y values and the mean of Y. The denominator is just the sample size less 1.
![]()
This is the equation for correlation. The numerator is the covariance above, and the denominator is the product of the two standard deviations of X and Y.
So now it’s number time!
Covariance
Here are the values for the X and Y variables:
X
4 5 6 7 8 9 10 11 12 13 14
Y
5.0 5.5 6.0 6.5 7.0 7.5 8.0 8.5 9.0 14.0 10.0
mean(X) = 9
mean(Y) = 7.09091
X - mean(X)
-5 -4 -3 -2 -1 0 1 2 3 4 5
Y - mean (Y)
-2.90909091 -2.40909091 -1.90909091 -1.40909091 -0.90909091 -0.40909091 0.09090909 0.59090909 1.09090909 6.09090909 2.09090909
sum(X - mean(X))*(Y - mean (Y))
73 (numerator)
n - 1
10
73/10 = 7.3 <- covariance!
So what does this all mean? As the value of the numerator decreases, the covariance will decrease too, right?
What’s in the numerator? The differences between all the X values and the mean of X and the differences between all the Y values and the mean of Y. As these differences decrease, even if one difference between and X value and the mean of X decreases, the numerator will decrease, and the covariance will decrease as well.
So what happens when we remove the outlier?
X (outlier removed)
4 5 6 7 8 9 10 11 12 14
Y (outlier removed)
5.0 5.5 6.0 6.5 7.0 7.5 8.0 8.5 9.0 10.0
mean(X) = 8.6
mean(Y) = 7.3
sum(X - mean(X))*(Y - mean (Y))
46.2 (numerator)
n - 1
9
46.2/9 = 5.133 <- covariance!
AHA! Smaller numerator = smaller covariance! Notice how the smaller denominator doesn’t really matter, as the ratio is still different.
Now what?
Correlation
sd(X) = 3.316625
sd(Y) = 2.528025
sd(X)*sd(Y) = 8.38451
7.3/8.38451 = 0.8706532 <- correlation!
Now we remove the outlier!
sd(X) = 3.204164
sd(Y) = 1.602082
sd(X)*sd(Y) = 5.133333
5.133/5.133 = 1 <- correlation!
The correlation, on the other hand, increases, as the variance of Y decreases due to the removed outlier (which has a large difference between the observed Y value and the mean value of Y).
Does anybody else think this is really cool, or is it just me?
It’s probably just me. Sorry.
Today’s song: Hoppípolla by Sigur Ros

