Blogger’s note: this is what Teddy Grahams do to me. Keep them away from me.
OKAY PEOPLE…another stats-related blog for y’all. Consider this nice little data set:

Isn’t it pretty? Let’s check out the covariance and correlation:
cov(x, y) = 7.3
cor(x, y) = 0.8706532
Now obviously that one point kind of hanging out there is an outlier, right? So let’s take it out:

Quick, before I do anything else—what do you think will happen to the correlation? What do you think will happen to the covariance?
This was a question for our regression practice midterm, but I heard someone today talking about covariance and correlation and they were completely WRONG…hence this blog. So I remember when I first got this question, I at first thought that both correlation and covariance should increase, but then that seemed like it wouldn’t make sense.
How do we tell?
Equation time!
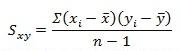
This is the equation for covariance. As you can see, in the numerator is the sum of the product of all the differences between all the X values and the mean of the X and the differences between the Y values and the mean of Y. The denominator is just the sample size less 1.
![]()
This is the equation for correlation. The numerator is the covariance above, and the denominator is the product of the two standard deviations of X and Y.
So now it’s number time!
Covariance
Here are the values for the X and Y variables:
X
4 5 6 7 8 9 10 11 12 13 14
Y
5.0 5.5 6.0 6.5 7.0 7.5 8.0 8.5 9.0 14.0 10.0
mean(X) = 9
mean(Y) = 7.09091
X - mean(X)
-5 -4 -3 -2 -1 0 1 2 3 4 5
Y - mean (Y)
-2.90909091 -2.40909091 -1.90909091 -1.40909091 -0.90909091 -0.40909091 0.09090909 0.59090909 1.09090909 6.09090909 2.09090909
sum(X - mean(X))*(Y - mean (Y))
73 (numerator)
n - 1
10
73/10 = 7.3 <- covariance!
So what does this all mean? As the value of the numerator decreases, the covariance will decrease too, right?
What’s in the numerator? The differences between all the X values and the mean of X and the differences between all the Y values and the mean of Y. As these differences decrease, even if one difference between and X value and the mean of X decreases, the numerator will decrease, and the covariance will decrease as well.
So what happens when we remove the outlier?
X (outlier removed)
4 5 6 7 8 9 10 11 12 14
Y (outlier removed)
5.0 5.5 6.0 6.5 7.0 7.5 8.0 8.5 9.0 10.0
mean(X) = 8.6
mean(Y) = 7.3
sum(X - mean(X))*(Y - mean (Y))
46.2 (numerator)
n - 1
9
46.2/9 = 5.133 <- covariance!
AHA! Smaller numerator = smaller covariance! Notice how the smaller denominator doesn’t really matter, as the ratio is still different.
Now what?
Correlation
sd(X) = 3.316625
sd(Y) = 2.528025
sd(X)*sd(Y) = 8.38451
7.3/8.38451 = 0.8706532 <- correlation!
Now we remove the outlier!
sd(X) = 3.204164
sd(Y) = 1.602082
sd(X)*sd(Y) = 5.133333
5.133/5.133 = 1 <- correlation!
The correlation, on the other hand, increases, as the variance of Y decreases due to the removed outlier (which has a large difference between the observed Y value and the mean value of Y).
Does anybody else think this is really cool, or is it just me?
It’s probably just me. Sorry.
Today’s song: Hoppípolla by Sigur Ros

