Learning About Letters (and being terrified of the letter “V”)
I’m pretty sure I’ve blogged about this before, but we had this on VHS when I was a kid and it’s still in my head somewhere.
Comments:
- The hair on that lilac Muppet at 1:51 always made me super happy. It looks like such a nice texture.
- “‘C’ is for Cookie” is a banger.
- The deadpan delivery of “Harry the Horse” at 9:05 is great.
- In Bert’s defense, “linoleum” is a pretty awesome word.
- That story for “V” (19:50) terrified me as a kid. I’d leave the room every time, haha.
- That segment from 21:09-22:38 was always one of my favorite parts.
Woo!
More Nostalgia Garbage
I found that “Goodnight Aneel” thing I posted about yesterday because I’ve been going through all the old crap on my compy. Another thing I found was a Word document full of all sorts of old letters/emails/etc. that I saved for whatever reason or another.
Back in elementary school (5th grade, 6th grade), one thing I liked to do (‘cause I was a weird bugger) was pretend that each person’s desk was like their house and had its own address and such. I’d write letters to people, put them in actual envelopes (with drawn-on fake stamps), and “deliver” them through our “postal service” (which was just me putting the letters in peoples’ desks during recess).
Here’s an example:
Joe Hazardus
200 Master St.
Mossy, ID 8384ME
Sir O the Second
2020 Ribbon St.
Mossy, ID 8384ME
Dear Sir O the Second:
It occurred to me that Mistress O has fallen from her tower again. She has no sense of balance. Anyway, you don’t get the index concept. Don’t think Parlor Van Anita hasn’t called me yet. Cappi Bara still needs your opinion. Do you like plaid or velvet? Tell her soon, or behold her wrath!!!
T.S.T.B. Joe and Solid Cooler have decided to plan your day. I hope you’re happy. Fun with Pressure Points has caught the attention of millions. Do you think Grouper Sue and yourself could pull it off in front of the nation?
P.S. Lee Blubberlig and Hershe Wrapper are upset with you. Don’t ask me why.
Your Seedless Wonder who is DESPERATE for a reply,
Joe Hazardus
I was, of course, Joe Hazardus. Sir O the Second was Kelly O., I believe. Solid Cooler was John…I don’t remember who the others were. “T.S.T.B.” stood for “Too Soon To Be” because why not.
Here’s an email I sent to my friend Aneel in 7th grade. Having an email address was the hip n’ cool new thing at the time (2001). I was starpotty@hotmail.com. I was also hyper as hell, apparently.
Where are you? Are you in Arizona? Mexico? California? Tokyo? Do you still have this address? I hope so cause I’m sending you this. Do you have a brain you could spare? Do you have any Norwegian money? Turnips are good. I fail to see the similarities between a shoe and it’s laces of doom. Do you have any snowballs? I like the snow….maybe it’ll snow today. Somebody wants to copy an orange. Maybe if you build a pool and put gelatin in it, it will replicate the look and feel of an ocean. Turnips are disgusting. Can you spell? I can’t spell. My Halloween pumpkin tried to kill me last night. It seemed to go nuts and tried to declare freedom. Maybe I shouldn’t carve pumpkins anymore. Are you the king of your country yet? Has Tokyo sunk yet? Where’s your phone? I WANT THE DANG PHONE BACK!! HAVE YOU NO HEART?!!??!!? Oh well. Is it a cellular phone, or just one of those where you get this *eepbeepbeepbeepbeepbeep* and then “cosmic operator, hold, please” and then: DUN-DUN DUN DUN DUNNNN DU DU!DUN-DUN DUN DUN DUNNNN DU DU!DUN-DUN DUN DUN DUNNNN DU DU!DUN-DUN DUN DUN DUNNNN DU DU!DUN-DUN DUN DUN DUNNNN DU DU! and then you go and re invent the law of physics and cut a hole in the ceiling and get sucked into it. How many turnips have you grown since I started writing this dang message? Are you even reading this? HOW LONG WILL IT TAKE???? Are you in Tokyo yet? TIP: if you put an egg in the microwave for 2:00, at 1:39 seconds, it will EEEXPPLLOOODDDE!!!! It is very very loud…33,333,333,333,333,333,333,333 decimals, to be precise. Can you read this? ARE YOU SURE? I seriously doubt my instincts about sending you this…it’s not like you CHECK it very often. I’ve sent you, like, 4 billion freakin messages!! AND HOW DO YOU REPAY ME???? SILENCE!!! Oh, the horror! Oh, the insanity! Oh, the inconvenience!!!!!!!!!!! DEATH!!!!!!!!!!!!! *ahem* okay. Enough of that. See ya soooooooooooooooooooooooooooooooooon! bye.
>+<!*^*~(STAR POTTY)~^*^*!>+<
I also wrote a lot of love letters to the dude I liked back when I was a kid, but we ain’t gonna go into that nonsense.
Bias
Are there certain sounds and/or combinations of letters in the English language that you find unappealing, regardless of the words they’re in?
For example, I don’t like the long “o” sound (like in boat or moat or goat), but only if it’s spelled with “oa”. Tote and smote and wrote are fine.
Same with “s”. I only like that sound when it’s spelled with the “s”, like pass or summer or loose. I don’t like pace or rice or ceiling.
Words that end in “b” drive me nuts (job, crib, drab). Even if the “b” is silent (like in limb).
I’ve never really liked “w” in general.
Not a big fan of the long “e” sound, either, especially if it’s spelled with “ea”. Lease, east, peanut. Beer, Weedle, and peer are fine.
So what do I like?
I like the “k” and hard “c” sound. Coin, click, coffin.
I like “ch” and “tch”. Batch, cheddar, kitchen.
The “h” sound isn’t bad, either. Hoop, honor, rehire.
I like “v”, but only at the beginning of words. Vacancy, victorious, vanity. Not glove or rave or reverberate.
I dunno.
An Analysis of Letters
So if you recall, not too long ago I analyzed whether the frequencies of letters in the English language change depending on the letter of the word. To do so, I gathered about 5,000 English words and compared the frequency distributions of the letters for the first five letters of the words. Click here to check that out if you haven’t already done so.
I’d wanted to go further into the words, but I didn’t have time/data to do so.
So that’s what I did today!
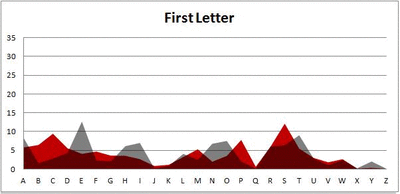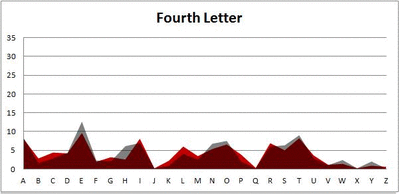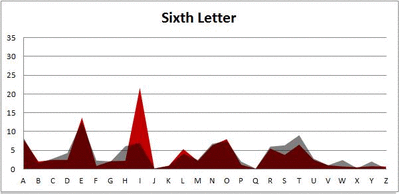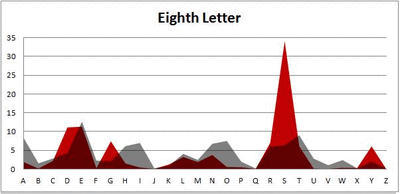
I pulled large samples of 4-, 5-, 6-, 7-, 8-, and 9-letter words from an online Scrabble dictionary*. For each sample, I went through and found the frequency distribution of the 26 letters of the alphabet for each letter place in the word (e.g., for the 4-letter words, I found the frequency distribution of the 26 letters for the first, second, third, and fourth place in the 4-letter word).
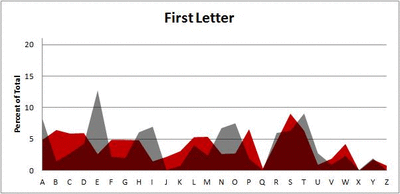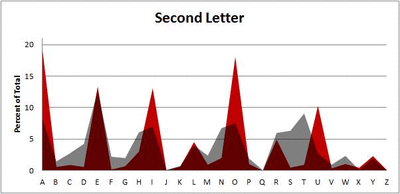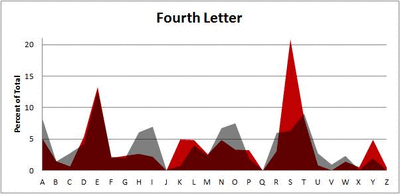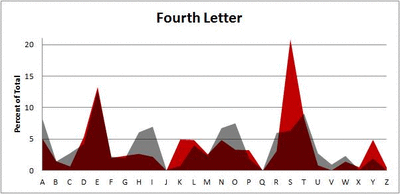
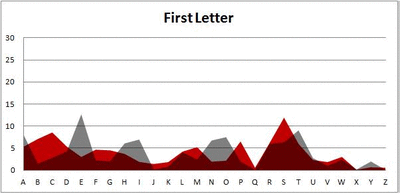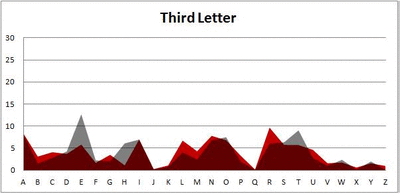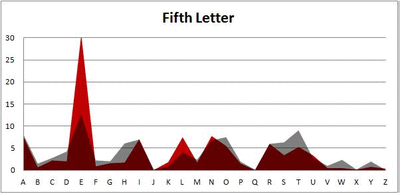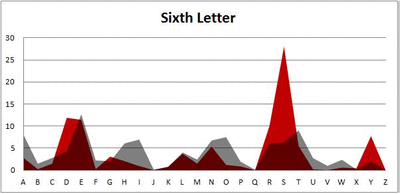
Because I think something like this is something that requires some sort of visual, I made a gif for each word size (4, 5, 6, 7, 8, 9 letters) that compares the letter frequency for each letter place in the word (in red) compared to the overall frequency of the letters in the entirety of the English language (grey). Check them all out and see if you notice a pattern as the gifs progress through the letter places in the words.
Four-letter words:
Five-letter words:

Six-letter words:
Seven-letter words:

Eight-letter words:
Nine-letter words:
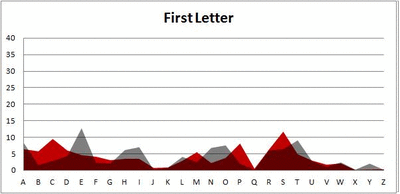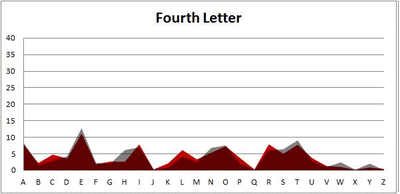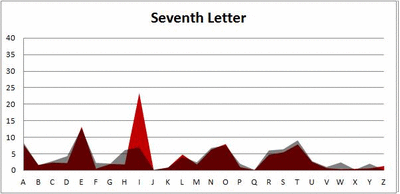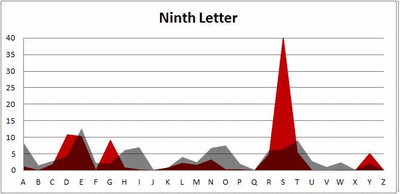
Did you notice it? Regardless of word size, the letter frequencies were most different from the overall frequency in the English language near the beginning and end of the words. Near the “middle” of the words (like the fourth and fifth letters of the nine-letter words, for example), the letter frequencies best matched the overall frequency in the English language (that is, the red distribution best matched the grey distribution).
In addition to the graphical aspect, I of course worked this out with numbers. Like last time, I measured “error” as the absolute value of the total difference between the red and grey distributions for each letter of each word. This confirmed what the gifs show: the smallest error was always for the one or two letters in the “middle” of each word, regardless of size.
Pretty damn cool, huh?
FYI, the six gifs sync and “restart” at the same time every 2,520 frames, in case you’re one of those people who wonders about those types of things.
*Yes, I realize the use of a Scrabble dictionary skews the results a bit, considering that plurals are included in the dictionary as well (notice the “S” is really frequent for the last letter in all cases). But plurals are words, after all, so I figured I’d include them anyway. The pattern still exists anyway even if you omit the last letter from all gifs.
Do babies deprived of disco exhibit a failure to jive?
You know, sometimes the most “pointless” analyses turn up the coolest stuff.
Today I had…get ready for it…FREE TIME! So I decided to try analyzing a fairly large dataset using SAS (’cause SAS can handle large datasets better than R and because I need to practice my coding anyway).
I went here to get a list of the 5,000 most common words in the English language. What I wanted to do was answer the following questions:
1. What is the frequency distribution of letters looking at just the first letter of each word?
2. Does the distribution in (1) differ from the overall distribution in the whole of the English language?
3. Does either frequency distribution hold for the second letter, third letter, etc.?
LET’S DO THIS!
So the frequency distribution of characters for the first letter of words is well-established. Wiki, of course, has a whole section on it. Note that this distribution is markedly different than the distribution when you consider the frequency of character use overall.
I found practically the same thing with my sample of 5,000 words.
So this wasn’t really anything too exciting.
What I did next, though, was to look at the frequencies for the next four letters (so the second letter of a word, the third letter, the fourth, and the fifth).
Now obviously there were many words in the top 5,000 that weren’t five letters long. So with each additional letter I did lose some data. But I adjusted the comparative percentages so that any difference we saw weren’t due to the data loss.
Anyway. So what I did was plot the “overall frequency” in grey—that is, the frequency of each letter in the whole of the English language—against the observed frequency in my sample of 5,000 words in red—again, for the first, second, third, fourth, and fifth letter of the word.
And what I found was actually really interesting. The further “into” a word we got, the closer the frequencies conformed to the overall frequency in the English language.

The x-axis is the letter (A=1, B=2,…Z=26). The y-axis is the number of instances out of a sample of 5,000 words. See how the red distribution gets closer in shape to the grey distribution as we move from the first to the fifth letter in the words? The “error”–the absolute value of the overall difference between the red and grey distributions–gets smaller with each further letter into the word.
I was going to go further into the words, but 1) I left my data at school and 2) I figured anyway that after five letters, I would find a substantial drop in data because there would be a much lower count of words that were 6+ letters long.
But anyway.
COOL, huh? It’s like a reverse Benford’s Law.*
*Edit: actually, now that I think about it, it’s not really a REVERSE Benford’s Law; as I found when I analyzed that pattern, it too rapidly disintegrated as we moved to the second and third digit in a given number and the frequency of the digits 0 – 9 conformed to the expected frequencies (1/10 each).
Artz n’ Letterz
So this is something I noticed a long time ago, but going through my playlists in iTunes this afternoon made the observation come to the forefront of my mind: when I sort my “Top Favorites” playlist by artist, I notice that a large amount of the songs (68%) are by artists whose names begin with a letter from the first half of the alphabet (A – M). When I sort my entire music library in this manner, I find the same proportion (okay, 67%…it’s pretty damn close). And you know what’s more interesting? If I sort by the TITLE of the song, I get the same proportion again! OOH, OOH, and sorting my freaking book list gives the same 67% as the music.
I find this quite fascinating. Has anyone else ever noticed this type of pattern in any of their things? It’s interesting to me that this 2:1 ratio keeps coming up. This requires exploration.
Hypothesis: this 2:1 ratio occurs because the first half of the alphabet contain more letters that appear more often as the first letters in English words.
Method: utilizing letterfrequency.org, I found the list of the frequencies of the most common letters appearing as the 1st letter in English words*. I used this list as a ranking and, using a point-biserial correlation, correlated this ranking with a dichotomized list of the letters, in which letters in the first half of the alphabet were assigned a value of “0” and those in the second half of the alphabet were assigned a value of “1.”
Results: here are the two values being correlated alongside their respective letters:

Where the “X” column is ranking by the frequency of appearance as the first letter of a word and the “Y” column is a dichotomized ranking by alphabetical order. Point-biserial correlation necessary because one of the variables is dichotomous. So what were the results of the correlation? rpb = .20, p = .163.
Conclusion: well, the correlation isn’t statistically significant (p < .05) by a long shot, but I’ll interpret it anyway. A positive correlation in this case means that letters with the larger dichotomy value (in this case, those coded “1”) tend to also be those same letters with a “worse” (or higher-value) coding when ranked by frequency as the first letter in English words. So in plain English: there is a positive correlation between letters appearing in the second half of the alphabet and their infrequency as their appearance as the first letter in English words. In other words, letters appearing in the first half of the alphabet are more likely to appear as the first letter in English words. Not statistically more likely, but more likely.
Meh. Would have been cooler if the correlation were significant, but what are you going to do? Data are data.
*Q, V, X, and Z were not listed in the ranking, but given the letters, I assume that they were so infrequent as first letters that they were all at the “bottom.” Therefore, that is where I put them.
Helvetica Headache
Well, this was going to be a small simple thing, but, as you know, that never is the case when I’m involved. So I now present to you a semi-objective ranking of the alphabet!
I decided that the letters would be judged according to six factors:
-Uppercase Aesthetic Value (visual) (UAV visual): aesthetic value based on visual appeal of uppercase letters typed in 40 pt. Arial.
-Lowercase Aesthetic Value (visual) (LAV visual): aesthetic value based on visual appeal of lowercase letters typed in 40 pt. Arial.
-Uppercase Aesthetic Value (written) (UAV written): aesthetic valued judged on ease* of written uppercase letters, in the style of Arial.
-Lowercase Aesthetic Value (written) (LAV written): aesthetic valued judged on ease* of written lowercase letters, in the style of Arial.
-Phonetic Aesthetic Value (PAV): aesthetic value judged on ease of spoken sound. Letters with multiple sounds had each sound ranked. The means of these rankings are reported.
-Aural Aesthetic Value (AAV): aesthetic value judged on appeal of spoken sound. Letters with multiple sounds had each sound ranked. The means of these rankings are reported here.
Here is the table of the rankings, followed by a column of the final ranked letters. Have fun (asterisks denote tied values)!

Waiter! There’s a quadriplegic in my Jazzercise class!
What’s up with me and the quadriplegic/paraplegic jokes? Anyway, down to business!*
*none of this should be taken seriously. Seriously.
An Exposition on Paleontology In Which Several Points Must Be Made
Point 1: In Which Is Written A Strongly-Worded Letter To Jack London
Dear Mr. London,
Having just read your short story “To Build a Fire,” I have several questions regarding the coldness of the territory in which your character, “the man,” was wandering about.
Repeated six times in 11 pages is some variation of the phrase, “it was cold.” Your exact words are:
“It certainly was cold, he concluded”,
“Once in a while the thought reiterated itself that it was very cold”,
“It certainly was cold”,
“It certainly was cold, was his thought”,
“There was no mistake about it, it was cold”, and
“It certainly was cold, was his thought”.
On completion of this story I found that there might be some confusion over whether or not it was cold in this Alaskan territory. Other readers and I would benefit greatly if you were to state clearly—on multiple occasions, perhaps, even repeating yourself—how cold it actually was (that is, if it was cold at all).
Thank you in advance,
Sir Isaac Newton (not that one, a different one).
Point 2: In Which The Riddle Of The Double-Dream-Marriage To William Shatner Is Discussed
Dear Brain,
It has come to my attention that you, on more occasions than one, have found it rather humorous to have me marry William Shatner in my dreams. This has occurred now both in the months of February and March.
While William Shatner is indeed a dignified character, and while we both share several similar activities and hobbies, such as appearing in Kellog’s All-Bran cereal commercials on the side (thank you, Wikipedia), I do feel it is time for a change.
I would appreciate it, my dear Brain, if you would delve into the past a bit, and conjure up images of Voltaire, Descartes, or Locke. Seeing as how Voltaire is the only man who dared show a smirk in his portraits, I would prefer him.
Oh Brain, how I wish for Voltaire in my dreams tonight.
Thank you in advance,
Me (you know me, don’t you?).
Point 3: In Which My Severe Aversion To Romanticism And My Longing To Return To The Study Of The Enlightenment Is Discussed
Dear English Department,
While I realize how necessary it is to delve into all forms and time periods of English literature, I do strongly recommend that we return to the study of the Enlightenment. It is so much more intriguing and enchanting than Romanticism. While Frankenstein’s creation and Rousseau’s raunchy “Confessions” do it for some, others, like myself, prefer the wit of Voltaire and the steady reasoning logic of Descartes.
Please see Point 2 above, disregarding the first part about Mr. Shatner.
Thank you in advance,
Some Random Student.

