Exploratory Data Analysis Project 3: Make a Pretty Graph in R (NOT as easy as it sounds)
Seriously, the code to make the graphs is longer than the code to extract the individual lists of digits from the random number vector.
Anyway.
The goal was to show a simple yet informative demonstration of Benford’s Law. This law states that with most types of data, the leading digit is a 1 almost one-third of the time, with that probability decreasing as the digit (from 1 to 9) increases. That is, rather than the probability of being a leading digit being equal for each number 1 through 9 the probabilities range from about 30% (for a 1) to about a 4% (for a 9).
For the first graph, I wanted to show how quickly the law breaks down after the leading digit (that is, I wanted to see if the second and third digit distributions were more uniform). I took a set of 10,000 randomly generated numbers, took the first three digits of each number, and created a data set out of them. I then calculated the proportion of 1’s, 2’s, 3’s…9’s in each digit place and plotted them against Benford’s proposed proportions. Because it took me literally two hours to plot those stupid errors of estimate lines correctly (the vertical red ones), I just did them for the leading digit.
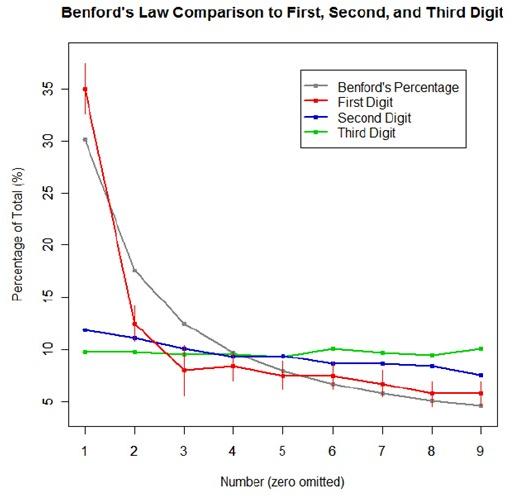
For the second graph, I took a data table from Wikipedia that listed the size of over 1,000 lakes in Minnesota (hooray for Wiki and their large data sets). I split the data so that I had only the first number of the size of the lakes, then calculated the proportion of each number. I left out the zeros for consistency’s sake. I did the same with the first 10,000 digits of pi, leaving out the zeros and counting each number as a single datum. I wanted to see, from the second graph, how Benford’s law applied to “real life” data and to a supposedly uniformly-distributed set of data (pi!).

Yes, this stuff is absolutely riveting to me. I had SO MUCH FUN doing this.

