Silly Claudia Idea #3144:
What would happen if famous books were really all about statistics?
- The Trial would become The Bernoulli Trial
- The Count of Monte Cristo would become The Count of Monte Carlo
- Great Expectations would become Great Expected Values
- The Old Man and the Sea would become The Old Man and the C-Test
- The Wonderful Wizard of Oz would become The Wonderful Wizard of Odds
- The Bell Jar would become The Bell Curve…though of course, there already is a book called The Bell Curve, so how about this: For Whom the Bell Tolls would become For Whom the Bell Curves
- The Kite Runner would become The Code Runner
- The Sun Also Rises would become The Sum Also Rises
And finally,
- One Day in the Life of Ivan Denisovich would become One Day in the Life of Ivan Denisovich is Not a Large Enough Sample Size to Allow Us to Make Claims About the Average Day of Ivan Denisovich.
MAKE IT HAPPEN!
(Sorry, I’m super nervous for tomorrow and thus am making zero sense today.)
Stats from the Past
While digging through the book bin at the recycling center, I came across this awesome find:

It’s a stats book from 1951!
It was really interesting looking through this, ‘cause this book was published way before SPSS, SAS, R, or any other software (at least, any other stats-centric software) was readily available.
Thus, we get examples in which all the calculations are done using the formulas rather than being read from an output table. Here’s some regression:

And t-scores:

And of course the t-table (in graphical format):
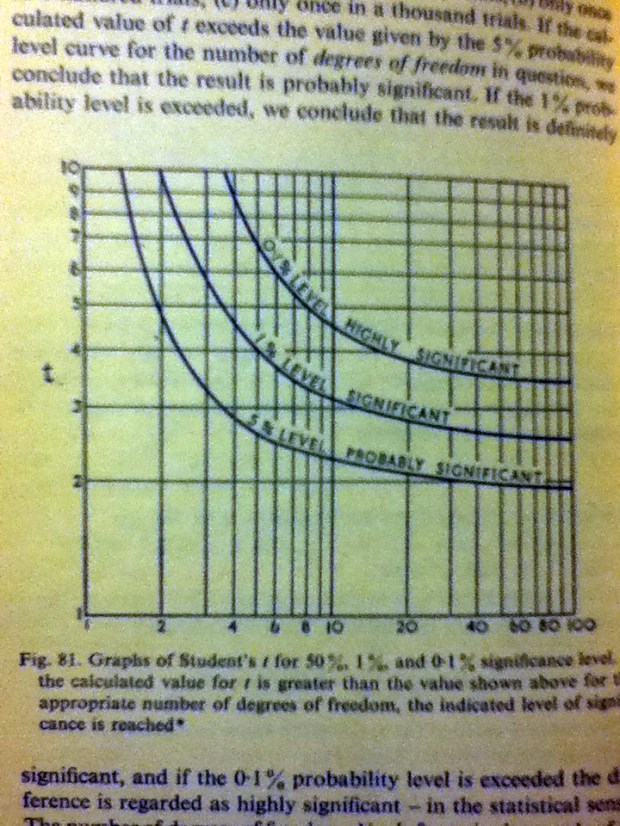
I didn’t even teach how to read a t-table in STAT 251. It was mainly because we just didn’t have time to do so, but considering we have ALL THE SOFTWARE today and, for all practical purposes, that’s what people use in “real life” nowadays, I focused instead on how to read output (and how to appropriately interpret it, of course!). I did have a separate sheet on how to understand a t-table that students could check out on their own if they wanted.
I’d show you pics of the ANOVA calculations, but there are a lot of them, haha.
DONE!

