Do all path diagrams want to grow up to be models?
HI!
Remember this?

This is probably the strangest result I found while writing my thesis. I’ll explain what it’s showing ‘cause it certainly isn’t obvious from this graph (especially if you don’t know structural equation modeling, aka SEM) and then tell you why I’d like to study something like this in depth.
SEM 101!
SEM is basically the process by which researchers attempt to construct models of the relationships amongst variables that best fit a given data set. For example, if the data I’m interested in are a bunch of variables related to the Big Five personality factors and I as a researcher have evidence to support a specific structure of relationships amongst these variables and factors, I can construct a structural equation model that numerically represents how I think the variables are related. I can then test my model against the actual relationships amongst the variables in the actual data.
Fit indices, the whole topic of my thesis, are calculations which allow researchers to quantify the degree to which their hypothesized model accurately represents the real structure of the relationships amongst the variables in the data. Most fit indices range from 0 to 1, though the meaning of scores of 0 and 1 differ depending on the index. Model fit can be affected by a bunch of stuff, but most obviously (and importantly) it is affected by inaccuracies in the hypothesized model.
For example, say I had a model in which I had variable A, variable B, and variable C all related to factor X but all uncorrelated with one another (good luck with that setup, but it’s good for this example). I fit this to data which, indeed, has A, B, and C all related to X but also has B and C covarying via their errors. The fact that my model is missing this covariation would factor into the calculation of the fit index, lowering its value.

Got it?
Okay.
Without going into the gory details of how these simulations were constructed and what model misspecification we added so that the fit index would have a discrepancy to work with (that is, the proposed model in the simulations purposefully didn’t match the underlying structure of the data and thus would have a fit index indicating a certain degree of misspecification), I’ll tell you what we did for this plot. I’ll tell you as I describe the plot, actually, ‘cause I think that’d be easiest.
Recall from like 20 sentences ago: SEM is about creating an accurate representation of the real relationships that exist amongst a set of variables. This representation of the true relationships amongst the data (called the “true model”) takes the form of a researcher’s proposed model (called the “hypothesized model”). I’ve labeled the pic above appropriately.
For the plot at the beginning of this blog, there were actually 18 simulated models—each with two factors and 24 indicator variables. The only differences between each of these models was how many indicator variables loaded onto the two factors. For example, one model looked like this (click to make these pics bigger, BTW):

(Three indicator variables loading onto Factor 1, 21 indicator variables loading onto Factor 2)
And another model looked like this:

(An equal number of indicator variables (12) loading onto both Factor 1 and Factor 2).
For each model, all the errors of the indicators were uncorrelated except for V1 and V2 (indicated by the crappily-drawn red arrows). You don’t really need to know what that means to get the rest of this blog; basically all you need to know is that each of the models had one extra “path” (or relationship between variables) in addition to the relationship between the two factors and the 24 indicator-to-factor relationships. So for each model, there totaled a number of 26 pathways or relationships between variables.
Now remember, I said these were simulated models. These models are actually what the data I created are arising from. Hence, they can be considered in the context of SEM as “true models” (see above).
Okay, so we’ve got a bunch of true models. How in the heck do we assess the performance of fit indices?
Easy! By creating a “hypothesized model” that (purposefully, in this case) omits a pathway that’s actually present in the data arising from the true model. In this simulation, that meant that for each true model, there would be a hypothesized model created that would fit every path correctly BUT would omit the correlation between the errors for V1 and V2 (the red-arrow-represented relationship between V1 and V2 would not exist in the hypothesized model).
See what I’m getting at? I’m purposefully creating a hypothesized model that doesn’t fit the true model exactly so that I can analyze what fit indices appropriately reflect the discrepancy. Indices that freak out and say “OH YOUR MODEL SUCKS, IT’S TOTALLY NOT AN ACCURATE REPRESENTATION OF THE UNDERLYING DATA STRUCTURE AT ALL” would be too sensitive, as a model that accurately represents 25 out of 26 possible pathways is a pretty damn good one (and is almost unheard of in psychology-related data). However, an index that says, “Hey, you’re a pretty badass researcher, ‘cause your model fits PERFECTLY!” isnt’ right either; you’re missing a whole pathway, how can the fit be perfect?
ANYWAY.
Wow, that was like 20 paragraphs longer than I was expecting.
[INTERMISSON TIME! Go grab some popcorn or something. I’m watching Chicago Hope at the moment, actually. Love that show. Thank you, Hulu. INTERMISSION OVER!]
Back to the plot.
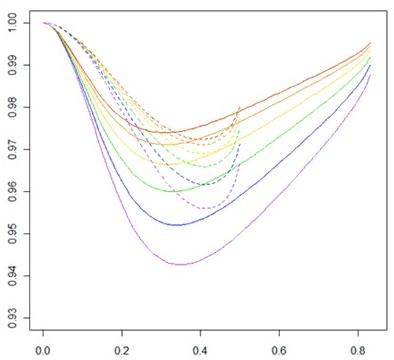
So now you know what the models were in this case, I can tell you that the x-axis of this plot represents the 18 different models I had created. You’ll note the axis label states “# of Indicators per Factor with Misspecification.” This means that for the tick labeled “3,” the correlated errors of V1 and V2 in the true model occurred under the factor with three variables (with the other factor, Factor 2, having the remaining 21 indicator variables loading onto it). The hypothesized model, then, which omits this relationship, looks like this:

On the opposite side of the plot then, the tick labeled “21” is opposite—the error covariance occurs between variables that load onto the factor with the 21 indicator variables loading onto it.
Make sense?
Probably not ‘cause I’m writing this at like 5 AM and sleep is for wusses and thus I haven’t been partaking in much of it, but I SHALL CARRY ON FOR THE GOOD OF THE NATION!
Remember, for each of the 18 true models, I fit a hypothesized model that matched the true model perfectly, except it OMITTED the error covariance occurring between two indicator variables.
Now let’s look at the y-axis, shall we? You’ll see it’s label reads “SRMR,” which stands for the Standardized Root Mean Square Residual fit index. This index, as can be seen by the y-axis values, ranges from 0 to 1. The closer the index gets to 1, the better the hypothesized model is said to fit the true model, or the true underlying structure of the data.
Okay, and NOW let’s look at the colored lines. The different colors represent the different strengths of correlation between the two factors in the model. But that’s probably the least important thing right now. So I guess just ignore them, haha, sorry.
Alrighty. Now that you (hopefully kind of sort of) mucked through my crappy, haphazard, rushed explanation of what this graph is showing, take a look at it, particularly at how the lines change as you move left to right on the x-axis.
Do you all see how weird of a pattern that is? This plot is basically showing me that the fit index SRMR is sensitive to misspecification in the form of an omitted pathway (relationship between variables), but that this sensitivity jumps all over the damn place depending on the size of the factor on which it occurs. Notice how all the lines take a dive toward a y-axis value of zero (poor fit) when there 7 indicators belonging to the factor containing the misspecification (and 17 indicators belonging to the factor without the misspecification). Isn’t that WEIRD? Why in the hell does that particular shaped model have such a poor fit according to this index? Why does fit magically improve once this 7:17 ratio is surpassed and more indicator variables per the factor with the error are included?* By the way, that’s this model:

Freaking SRMR, man. And the worst part of all this is the fact that this is NOT such an aberrant result. ALL of the fit indices I looked at (I looked at seven of them), at least once, performed really, really poorly/counter-intuitively.
This is why this stuff needs studying, yo. Also why new and better indices need to be developed.
Haha, okay, I’m done. Sorry for that.
*Actually this sort of makes sense—the more indicator variables there are loading onto the factor with the error, the more “diluted” that error becomes and it’s harder for fit indices to pick it up. However, there’s not really an explanation as to why the fit takes a dive UP TO the 7:17 ratio.
Three Points of Fantastic Insignificance and One Point of Moderate Meh
FANTASTIC INSIGNIFICANCE:
1. I really like the word “toast.” I also really like toasters. Especially brave ones.
2. Yay, I can still run 10k in under an hour, even after not running since August!
3. I found the perfect job for me. Unfortunately, it’s at Twitter and I don’t know if I could go on living with myself if I worked for Twitter. Google, maybe (ASSIMILATION). Twitter? No.
MODERATE MEH:
Another goal I want to add to my New Year’s Resolution list is this: I want to try and make some progress on a new SEM fit index, one that works better overall than the current popular ones. While I don’t think we’ll ever arrive at an index that is as error free as we’re hoping to find, I think there is currently still a lot of room for improvement.
For example, the CFI works very well for detecting discrepancies between the model and the actual data when the discrepancies are at the latent level (e.g., the researcher’s model proposes two latent variables but the model underlying the actual data in reality has three) but does horribly at properly reflecting the degree of misspecification when there are error covariances omitted from a model (CFI shows excellent fit when the omitted error covariance is low or very high; it shows terrible fit when the omission is moderate in size).
I thought I had this super awesome idea the other day to apply a sort of bootstrapping mechanism to act as a fit index, but that’s already been thought up and either a) doesn’t work very well or b) is very hard to implement, as there are several papers on a bootstrap-like fit index but little documentation of the use of it (I didn’t come across it at all during my lit reviews). So maybe I’ll do some more research into that…perhaps my idea of how bootstrapping should be implemented in assessing fit is different (and probably way more incorrect…but whatever).
There are also transformations to look at, too, which would require examining how the minimum fit function changes as the size of the misspecification (as well as the TYPE of misspecification) changes.
You know what all this means? PARTY TIME WITH R!
I might as well be dating it, it’s not like I’ll ever have a boyfriend again.
But that’s okay. R!
Pretty R
I love R. This is an established fact in the universe. The only thing I love more than R is revising code I’ve written for it.
For my thesis, I had to make a metric ton of plots. For each scenario I ran, I ran it for seven different fit indices. I included plots for four of these indices for every scenario. With a total of 26 scenarios, that’s a grand total of 104 plots (and one of the reasons why my thesis was 217 pages long).
Normally, once I write code for something and know it works, I like to take the time to clean up the code so that it’s short, as self-explanatory as possible, and given notations in places where it’s not self-explanatory. In the case of my thesis, however, my goal was not “make pretty code” but rather “crap out as many of these plots as fast as possible.” Thus, rather than taking the time to write code that would basically automate the plot-making process and only force me to change one or two lines for each different plot and scenario, I basically made new code for each and every single plot.
In hindsight, I realize that probably cost me way more time than just sitting down and making a “template plot” code would have. In fact, I now know that it would have taken less time, as I have made it my project over the past few days to actually go back and create such code for a template plot that I could easily extend to all plots and all scenarios.
Side note: I’m going to be sharing code here, so if you have absolutely no interest in this at all, I suggest you stop reading now and skip down to today’s meme to conclude today’s blog.
This code is old code for a plot of the comparative fit index’s (CFI’s) behavior for a 1-factor model with eight indicators for an increasingly large omitted error correlation (for six different loading sizes; those are the colored lines). As you can see in the file, there are quite a few (okay, a lot) of lines “commented out,” as indicated by the pound signs in front of the lines of code. This is because for each chunk of code, I had to write a specific line for each of the different plots. Each of these customizing lines took quite awhile to get correct, as many of them refer to plotting the “λ = some number” labels at the correct coordinates as well as making sure the axis labels are accurate.
This other code, on the other hand, is one in which I need to change only the data file and the name of the y-axis. It’s a lot cleaner in the sense that there’s not a lot of messy commented out lines, lines are annotated regarding what they do, and—best of all—this took me maybe five hours to create but would make creating 104 plots so easy. Some of the aspects of “automating” plot-making were somewhat difficult to figure out, like making it so that the y-axis would be appropriately segmented labeled in all cases, and thus the code is still kind of messy in some places, but it’s a lot better than it was. Plus, now that I know that this shortened code works, I can go back in and make it even more simplified and streamlined.
Side-by-side comparison, old vs. new, respectively:

Yeah, I know it’s not perfect, but it’s pretty freaking good considering I have to change like two lines of the code to get it to do a plot for another fit index. Huzzah!
30-Day Meme – Day 17: An art piece (painting, drawing, sculpture, etc.) that is your favorite.
As much as I love Dali’s Persistence of Memory, I have to say that one of my favorite paintings is Piet Mondrian’s Composition with Red, Blue, and Yellow.

It’s ridiculously simple, but that’s what I like about it. There’s quite a lot of art I don’t “get” and I think Mondrian’s work may fall into that category. However, there’s something implicitly appealing about this to me. I love stuff that just uses primary colors and I really like squares/straight lines/structure. So I guess this is just a pretty culmination of all that.
TWSB: Weebles Wobble (But They Wouldn’t if They Had Three Legs)
You know those “duh” phenomena or experiences that you come across every day? You know, the ones that you would think would have a simple explanation for why they occur but have never actually asked yourself? Those make the best TWSBs.
Take today’s topic, for example: why a three-legged stool is stable, while a four-legged stool (or any higher-legged stool, though I’m pretty sure octuple-legged stools are quite rare) often wobbles.
This article here talks about the fundamentals of why this is. It uses the analogy of a cane: suppose you’re holding a cane unrestrained in the air. You can twirl it in any direction possible, in all three dimensions. Now suppose you set one end of the cane on the ground. You’ve now constrained its motion to two dimensions (you can’t lift or rotate it). Next? Take a pair of canes, connect the tops, and place the other two ends on the ground in a little triangle of cane, cane, ground. The tops are still movable, but only along an arc. The motion is now constrained to one dimension. If you do the same thing with three canes? Can’t move the top at all. Now motion is constrained in all three dimensions, meaning the canes cannot be moved at all. As the article puts it, “each time you add a cane, you remove one dimension in which the top can move freely – that is, each new cane removes one ‘degree of freedom.”
At this point I had to stop and have a little stats freak out, ‘cause this means that stool-leggedness is almost perfectly analogous to model identification in structural equation modeling.
So let’s check that out, shall we?
A structural equation model is made up of variables and parameters (paths between variables, either dependent or independent, and paths between variables and errors). Parameters are, in other words, covariances between the variables. In this example, parameters are analogous to the dimensions in which the stool’s legs can rotate (so # of parameters = 3).
The number of covariances in any given model is called the number of “known values.” In the case of the stool, the number of legs the stool has is analogous to the number of known parameters in a model.
A just-identified (or saturated) structural equation model is one for which the number of parameters is equal to the number of known values. Such a model has zero degrees of freedom (since df = number of known values minus the number of parameters). A three-legged stool is like such a model, since df: 3 parameters – 3 known values = 0). A just-identified model has only one unique solution. The stool, analogously, has only one “solution” in the sense that there are exactly three legs used to stabilize the stool on the plane that is the ground.
Give the stool any more legs, though, and it becomes like an over-identified model, or one for which there are more known values (four in the case of a four-legged stool) than parameters (still only three dimensions in which the stool’s legs can rotate). An over-identified model, unlike a just-identified model, does not have a single unique solution, owing to the non-zero number of degrees of freedom. As the article puts it, “…now you have too many constraints. This means that there are multiple ways that the stool can “solve” the problem of which legs to use for support.”
Statistics analogies FTW!
Haha, sorry, this was a longer blog than originally planned. It got me excited.
In This Blog: My Data Look like a Napkin Swan

Seriously, standardized root mean square residual? Seriously?
This pattern makes absolutely no sense. It’s pretty, but it makes absolutely no sense.
I feel like this plot should be on Maury or something. “When Bad Patterns Happen to Good Data.”
I’d totally watch that.
Data, data everywhere and not a model to fit
Things a normal person does to relax:
– sleeps
– hangs out with friends
– copious amounts of alcohol
– screws around
Things Claudia does to relax:
– ignores sleep
– locks herself in her apartment
– copious amounts of Red Bull
– fits a structural equation model to her music data
Yeah.
I’ve spent a cumulative 60+ hours solely on my thesis writing this week, and considering all the other crap I had to finish, what with the semester ending and all, that’s a pretty large amount of time.
Despite that, it’s pretty sad that I spent my first few hours of free time this week fitting an SEM to my music.
BUT IT HAPPENED, so here it is.
With “number of stars” the variable I was most interested in, I wanted to fit what I considered to be a reasonable model that showed the relationships between the number of stars a song eventually received from me (I rarely if ever change the number after I’ve assigned the stars) and other variables, such as play count and date acquired. Note: structural equation modeling is like doing a bunch of regressions at once, allowing you to fit more complicated models and to see where misfit most likely occurs.
Cool? Cool.
Onward.

This is the initial model I proposed. The one-way arrows indicate causal relationships (e.g., there is a causal relationship in my proposed model between the genre of a song and the number of stars it has), the double-headed arrow indicates a general correlation without direction. Oh, and “genre” was coded with numbers 1 through 11, with lower numbers indicating my least favorite genres and higher numbers indicating my favorite genres. Important for later.
Using robust maximum likelihood estimation (because of severe nonnormality), I tested this model in terms of its ability to describe the covariance structure evident in the sample (which, in this case, is the 365 songs I downloaded last year).
So here’s what we got!
Satorra-Bentler scaled χ2(7) = 9.68, p = 0.207
Robust CFI: .992
Robust RMSEA: .032
Average absolute standardized residual: 0.0190
All these stats indicate a pretty awesome fit of the model to the data. This is shocking, considering ridiculous non-normality in the data itself and the fact that this is the first model I tried.
Here are the standardized pathway values (analogous to regression coefficients, so if you know what those mean, you can interpret these), with the significant values marked with asterisks:

So what’s this all mean? Well, in general, the relationships I’ve suggested with this model are, according to the stats, a good representation of the actual relationships existing among the variables in real life. Specifically:
– There is a significant positive relationship between genre and play count, which makes sense. Songs from my more preferred genres are played more often.
– There is a strong positive relationship between play count and stars, which also obviously makes a lot of sense.
– The significant negative relationship between date added and play count makes sense as well; the more recently downloaded songs (those with high “date added” numbers) have been played less frequently than older songs.
– There is no significant correlation between genre and song length, which surprises me.
– Genre, length, and play count all have significant, direct effects on how many stars I give a song.
– Another interesting finding is the positive relationship between stars and skips, which suggests that the higher number of stars a song has, the more often it is skipped. Perhaps this is just due to the sheer number of times I play the higher-starred songs. Who knows?
Yay! Fun times indeed.
The Beauty of Non-Monotone Relationships
My graphs speak for themselves. They make me very happy. Also, they’re not supposed to be making weird patterns like they are, but it’s still cool.


Yes, this is my research.

