Party all the time
(This is just an excuse to do a dinky little statistical analysis. Because I’m feeling analysis-deprived tonight.)
Long ago (2011) I took a series of online quizzes to figure out when the internet thought my average age of death was (which is a super valid prediction method, right?). Because I’m bored and have no life whatsoever, I’ve decided to re-take those same quizzes today and see if there is a statistically significant difference in the mean age of my death according to the internet.
GO!
The Data:
Year2011 year2015 86 87 70 67 79 79 90 84 89 89 85 85 91 90 85 85
Method: Since this is me just repeating a bunch of tests I’d taken before, this calls for a paired t-test!
H0: there is no difference in the means for 2011 and 2015
Ha: there is a difference in the means for 2011 and 2015
Results: The difference of the sample means is 1.125. With t = 1.3864, p-value = 0.282, we do not have significant evidence to reject the null hypothesis that there is no difference in the means for 2011 and 2015
Basic conclusion: My average lifespan (according to the internet) has neither increased nor decreased since 2011.
The end.
Sorry I’m so boring.
“Trompe l’oeil” is a fantastic phrase
HEY FOOLIOS!
So I’ve always had this suspicion that, on average, grades are better in the spring semesters than in the fall.
And because I’m an idiot, I didn’t find this until just now.
So let’s do some analyses!
The U of I has data from fall 2003 until fall 2013. I decided to use the “all student average” value for my analysis, and I also decided to do a paired means test where the “pairs” were made up of the average for the fall semester paired with the average for the following spring semester. Since most students start in any given fall semester and graduate in any given spring semester, it made the most sense to thing of fall-spring sets, since a fall semester and the following spring semester would most likely be made up of most of the same students, at least in comparison to any other pairing.
Also, there are a total of 10 pairs, so the sample size is OBSCENELY SMALL, but I’m doing it anyway.
Here we go!
Hypothesis: the average GPA for a year of UI students will be lower in the fall than in the spring. In other words, µfall < µspring.
Method: averages were collected for all spring and fall semesters between fall 2003 and spring 2012. Fall and subsequent spring semesters were paired.
Analysis: a paired t-test was performed on the 10 pairs of data and the above hypothesis was tested at an α = .05 level.
Results: here’s the table!
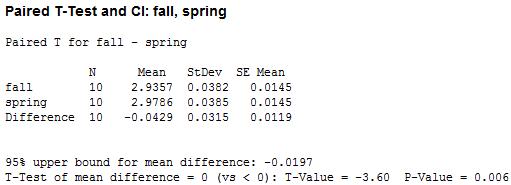
We’ve got a small p-value! That suggests, at a .05 level, that we can reject the hypothesis that the average GPA in fall and spring are equal and conclude in favor of the hypothesis that average GPA is lower in the fall than in the spring.

WOO!
Statistics in the Nude
HAHA, you wish, right?
Today (or yesterday, or some time recently) CNN.com put up a link to the 100 most popular boy and girl baby names of 2011. Said link is here.
My personal opinions:
- Hate the name Aiden
- Dig the name Sophia
- Annabelle’s my kitty’s name!
- Xavier? Really?
- What’s with the excessive overuse of “y” as a replacement vowel for…well, pretty much every other vowel?
- Half of these names I would never expect to be in the 100 most popular for this year.
Anyway.
Me being me, I decided to run a few quick little stats to see what’s what with these names. Consider this a delightful little romp through basic descriptive and inferencial stats.
- Test 1: Is there a difference between the mean number of syllables in the 100 most popular names for boys vs. the 100 most popular names for girls? (2-sample t-test)
- Test 2: Is there a difference between the mean syllable of emphasis in the 100 most popular names for boys vs. the 100 most popular names for girls? (2-sample t-test)
- Test 3: Do either the number of syllables or the mean syllable of emphasis statistically predict the rank of the names for either boys or girls? (Regressions! Regressions!)
Since these are small baby analyses I won’t go through the analyses in depth; I’ll just give you the results.
Test 1
I wanted to determine with this test if the top 100 male and 100 female names had a statistically different number of syllables. No names in either list had more than 4 syllables.
Mean number of syllables for male names: 2.45
Mean number of syllables for female names: 2.09
Results of the t-test: t(187.956) = 3.80, p < 0.001 (0.0001967)
This means that there is a statistically significant difference in the number of syllables in the 100 most popular male names and the 100 most popular female names (with male names having, on average, more syllables).
Test 2
I wanted to see if there was any difference between the two lists of names in terms of where the emphasis was placed in the name. Did one list contain more names where the emphasis was on the first syllable (e.g., “E-than,” “KA-thy”, “CA-ro-line”), or more names where the emphasis was later in the name (e.g. “a-LEX-a,” “nath-AN-iel,” “el-ISE”)? This was simplified somewhat by my coding; I just had “1,” “2,” “3,” and “4” as the codes for the emphasis falling on the first, second, third, or fourth syllable, respectively.
Mean syllable of emphasis for male names: 1.09
Mean syllable of emphasis for female names: 1.29
Results of the t-test: t(167.09) = 3.04, p = 0.0027
This means that there is a statistically significant difference between the location of the syllable of emphasis in the 100 post popular male names and the 100 most popular female names (with the emphasis being placed earlier in the name for males than females).
Test 3
I didn’t save the printout results of the regressions because afterward I realized how bad it was to attempt an inferential statistic with such a pittance of a data set, but I figured I’d let you know what I got anyway: performing a Poisson regression (y variable is a count variable, bitches!) revealed that neither the number of syllables nor the location of the emphasis in the name were statistically significant predictors of the rank of the names.
Ta-da!
Essentially, this is frivolity and I should be stopped
Alternate title: LOL BLOG 666 OMG WERE ALL GOING TO DIE!!!11!!ONE!!!
Now that the formalities are over I’d like to get right to the point: I’ve finally decided on what I’m going to analyze with a two-sample t-test in regards to my blogs.
I shall compare my “happy” blogs to my “sad” blogs (both terms to be defined further down) on various constituents (also to be defined further down).
Are you all ready for this?!?!
Goal:
Compare “sad” blogs and “happy” blogs on four independent points: number of words, number of smilies, number of exclamation points (indicative of excitement, frustration, flabbergastment, emphasis), and number of words in italics and/or in all caps (indicative of essentially the same things as exclamation points, but slightly cooler).
Definitions:
~”Happy” blog: a blog in which the mood is set to something indicative of a happy mood or an excited mood (amused, thrilled, silly, relieved, geeky/nerdy/dorky, and, of course, happy*).
~”Sad” blog: a blog in which the mood is set to something indicative of sadness, frustration, or anger (pissed, peeved, depressed, melancholy, sad, frustrated, angry*).
~Number of words: number of words in the body of the blog. The title/headings and the comments are not counted in this total.
~Number of smilies: just what it sounds like. Smilies like “:)” or “:P” used in chat dialogues are not counted.
~Number of exclamation points: as in this: !, not the number of times I say “exclamation points.”
~Number of words in italics and/or in all caps: this or THIS or THIS all count.
Method:
1) Generate an SRS of equal size n for both the happy blog data and the sad blog data
2) Collect data from said SRS
3) Analyze it in SAS
4) Bore you all to death with the results
Formulas in SAS:
proc univariate (for all variables)
proc ttest (for all variables, obviously the most important one if I’m doing t-tests!)
Procedure:
It was first figured that the population size was N = 665, as today’s blog was not counted amongst the viable samples. To determine an appropriate sample size for each category (happy and sad blogs), it was figured that a good n would amount to approximately 7% of the data. An n equal to 25 for both categories was used (thus having a total n = 50).
The blogs were numbered in a rather ingenious manner (thank you very much), and the SRS was obtained through sampling done with a random number table. If a blog obtained was deemed neither happy nor sad (indifferent blogs) it was disregarded and another random number was chosen in its place and sampling continued as normal.
Data was collected for both categories in all variables (see Raw Data) and was then analyzed using SAS. Results are displayed below in the Results section.
Raw data:
Data names: blogno; words; smilies; exclamations; italiccaps; happysad; 89 300 1 9 19 h 156 124 0 0 0 h 574 42 0 1 0 h 166 108 1 1 0 h 389 51 1 2 0 h 422 83 1 0 0 h 556 34 0 0 0 h 446 126 1 2 0 h 653 900 1 9 38 h 275 370 0 6 0 h 371 161 1 0 0 h 465 215 0 1 0 h 637 457 0 10 21 h 3 223 3 4 1 h 351 296 0 12 1 h 167 252 0 2 1 h 52 180 0 1 0 h 649 862 0 34 10 h 631 399 1 8 42 h 64 22 1 2 0 h 55 57 1 0 0 h 237 453 0 32 16 h 236 49 1 3 2 h 298 186 1 2 2 h 20 115 2 1 0 h 643 174 0 3 0 s 186 23 1 0 1 s 316 166 0 0 1 s 90 74 0 0 0 s 161 105 3 3 14 s 115 76 2 2 3 s 439 131 0 1 0 s 522 370 0 3 8 s 202 70 1 1 3 s 8 360 1 15 1 s 381 1258 0 18 38 s 468 128 0 0 2 s 12 59 0 0 0 s 41 21 0 0 0 s 474 174 1 0 0 s 425 459 0 0 0 s 265 236 0 2 1 s 311 64 1 0 0 s 363 5734 0 3 2 s 518 310 0 0 1 s 579 181 1 0 0 s 497 81 0 0 0 s 416 414 0 1 0 s 385 59 0 0 0 s
Results:
OH ARE YOU READY FOR THIS?! This is intense, people.
First up: the results of the univariate procedures for each variable. These data are for the whole sample, remember.
Words
Mean: 336.36 (standard deviation = 815.33)
Minimum: 21
Maximum: 5734
Smilies
Mean: 0.56 (standard deviation = 0.76)
Minimum: 0
Maximum: 3
Exclamation Points
Mean: 3.88 (standard deviation = 7.26)
Minimum: 0
Maximum: 34 (thirty-four exclamation points in a single blog? Good lord)
Italicized and/or All Caps Words
Mean: 4.56 (standard deviation =10.17)
Minimum: 0
Maximum: 42
Second: t-test results!
Words
Mean number of words in happy blogs: 242.6
Mean number of words in sad blogs: 430.12
Using –=.05, the results of the two-sample t-test showed that there was not a significant difference in the mean number of words in the two types of blogs. Though it sure looks like it from comparing the two, doesn’t it? That’s stats for ya.
Smilies
Mean number of smilies in a happy blog: 0.68
Mean number of smilies in a sad blog: 0.44
Sorry guys, this one isn’t showing a significant difference in the means, either. I guess I’m pretty constant with my particulars in my blogs, regardless of how I’m feeling.
Exclamation Points
Mean number of exclamation points in a happy blog: 5.68
Mean number of exclamation points in a sad blog: 2.08
Ooh, we were pretty close on this one! When I saw this result I was tempted to raise my alpha level to .1, thus making this one statistically significant, but then I figured that would be data manipulation, so I didn’t do it. Praise me!
Italicized and/or All Caps words
Mean number of italicized and/or words in all caps in a happy blog: 6.12
Mean number of italicized and/or words in all caps in a sad blog: 3
You guessed it—the means are not statistically significantly different. Strange, huh?
Now you may be thinking I did all this for nothing. Quite the contrary! We’ve learned from a sample of 50 blogs that, according to the data, my happy and sad blogs do not differ in a statistically significant manner on four key points. I find that interesting, myself.
As for you, well…you’re probably nodding off right now, so I’ll stop here.
*Does not encompass all moods used for defining the categories. I could have gone through and listed them all, but I’m too lazy for that.

