Back to nonparametrics this week with the Kruskal-Wallis one-way analysis of variance by ranks!
When Would You Use It?
The Kruskal-Wallis one-way analysis of variance by ranks is a nonparametric test used to determine if, in a set of k (k ≥ 2) independent samples, at least two of the samples represent populations with different median values.
What Type of Data?
The Kruskal-Wallis one-way analysis of variance by ranks requires ordinal data.
Test Assumptions
- Each sample of subjects has been randomly chosen from the population it represents.
- The k samples are independent of one another.
- The dependent variable (the values being ranked) is a continuous random variable.
- The distributions of the underlying populations are identical in shape (but do not have to be normal).
Test Process
Step 1: Formulate the null and alternative hypotheses. The null hypothesis claims that the k population medians are equal. The alternative hypothesis claims that at least two of the k population medians are different.
Step 2: Compute the test statistic, a chi-square value (usually denoted as H). H is computed as follows:
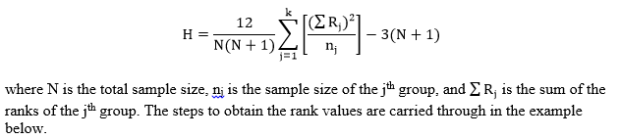
Step 3: Obtain the p-value associated with the calculated chi-square H statistic. The p-value indicates the probability of observing an H value equal to or larger than the observed H value from the sample under the assumption that the null hypothesis is true. The degrees of freedom for this test are k – 1.
Step 4: Determine the conclusion. If the p-value is larger than the prespecified α-level, fail to reject the null hypothesis (that is, retain the claim that the population medians are equal). If the p-value is smaller than the prespecified α-level, reject the null hypothesis in favor of the alternative.
Example
The example for this test comes from my music! Looking at my songs that are rated five stars, I wanted to see if there was a difference in the median playcounts for the different genres. Since my Five Star songs are mostly electronic and alternative, I decided to group the rest of the genres into an “other” category so that there are three genre categories total. Here, n = 50 and let α = 0.05.
H0: θelectronic = θalternative = θother
Ha: at least one pair of medians are different
To obtain the ranks of the songs, I did the following steps:
First, I sorted the songs by playcount.
Second, I ranked the songs from 1 to 50 based on their playcount, with 1 corresponding to the song with the highest playcount and 50 corresponding to the song with the lowest playcount. Note that I could have done this the opposite way (1 corresponding to the least-played song and 50 corresponding to the most-played song; the resulting H value would be the same).
Third, I adjusted the ranks for ties. Where there were ties in the playcount, I summed the ranks that were taken by the ties and then divided that value by the number of tied values. I then replaced the original ranks with the newly calculated value.
Finally, I summed the ranks within each of the three genre groups to obtain my Rj values. Here is a table of this final procedure:

Computations:
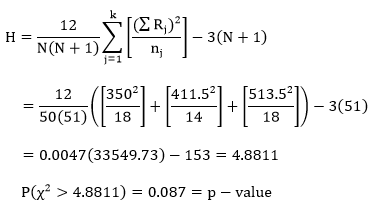
Here, our computed p-value is greater than our α-level, which leads us to fail to reject the null hypothesis, which is the claim that the median playcount is equal across the three genre groups.
Example in R
No example in R this week, as this is probably easier to do by hand than using R!

