Hello, all! Today we’re going to talk about a two sample test involving proportions. Specifically, we’re going to talk about the z test for two independent proportions!
When Would You Use It?
The z test for two independent proportions is a nonparametric test used to determine if, in a 2 x 2 contingency table, the underlying populations represented by the samples have equal proportions of observations in one of the two categories of the dependent variable.
What Type of Data?
The z test for two independent proportions requires categorical or nominal data.
Test Assumptions
- The data represent a random sample of independent observations.
Test Process
Step 1: Formulate the null and alternative hypotheses. The data appropriate for this type of test is usually summarized in a 2 x 2 table (see the example below to get a better understanding of this). The null hypothesis claims that for the category of interest of the dependent variable, the proportion of observations from the first category of the independent variable that belong to the category of interest is equal to the proportion of observations from the second category of the independent variable that belong to the category of interest.
Step 2: Compute the test statistic. The test statistic here is a z-score and is computed as follows:

Step 3: Obtain the p-value associated with the calculated z-score. The p-value indicates the probability of observing a difference in proportions as extreme or more extreme than the observed sample difference, under the assumption that the null hypothesis is true.
Step 4: Determine the conclusion. If the p-value is larger than the prespecified α-level, fail to reject the null hypothesis (that is, retain the claim that the proportions are equal in both groups of the independent variable). If the p-value is smaller than the prespecified α-level, reject the null hypothesis in favor of the alternative.
Example
For today’s example, I wanted to see if there was a significant difference in the proportion of gold medals for European countries versus the rest of the world in the 2012 London Summer Olympics. I sampled a total of 55 countries (all countries that won at least one gold medal), then tallied the number of gold medals, the number of non-gold medals, and whether or not the country was in Europe. This data is summarized in the following table:
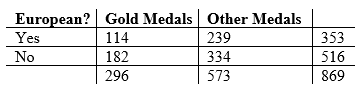
Let’s test the claim that the proportion of gold medals for European and non-European countries is different. Set α = 0.05.
H0: π1 = π2
Ha: π1 ≠ π2
Here, n1 = 353, n2 = 516, p1 = 0.323, and p2 = 0.353. The values of p and z and the resulting p-value are calculated as:
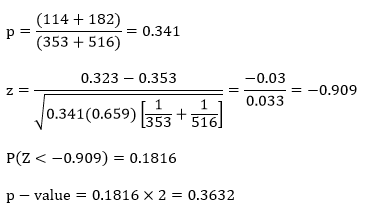
Since our p-value is larger than our alpha-level (0.3632 > 0.05), we fail to reject H0 and claim that the proportions are equal in the population.
Example in R
This example assumes that your data are in columns, with one column containing the number of gold medals per country, one column containing the number of total medals per country, and one coded column telling you whether a country belongs to Europe or not.
dat=read.table('clipboard', header=T) #'dat' is the name of the imported raw data
euro = subset(dat,europe == "y")
non = subset(dat,europe == "n")
a = sum(euro$gold)
b = sum(euro$total) - a
c = sum(non$gold)
d = sum(non$total) - c
n1 = sum(a + b)
n2 = sum(c + d)
goldsum = sum(dat$gold)
othersum = sum(total)
p1= a/n1
p2 = c/n2
p = (a + c)/(n1 + n2)
z = (p1 - p2)/(sqrt((p*(1-p))*((1/n1)+(1/n2))))
pval = (pnorm(z))*2 #p-value
#pnorm calculates the left-hand area
#multiply by two because it is a two-sided test

