Week 28: The van der Waerden Normal-Scores Test for k Independent Samples
Let’s look at another nonparametric test this week with the van der Waerden normal-scores test for k independent samples!
When Would You Use It?
The van der Waerden normal-scores test for k independent samples is a nonparametric test used to determine if k independend samples are derived from identical population distributions.
What Type of Data?
The van der Waerden normal-scores test for k independent samples requires ordinal data.
Test Assumptions
- Each sample of subjects has been randomly chosen from the population it represents.
- The k samples are independent of one another.
- The dependent variable (the values being ranked) is a continuous random variable.
- The samples’ underlying distributions are identical in shape (but do not necessarily have to be normal).
Test Process
Step 1: Formulate the null and alternative hypotheses. The null hypothesis claims that the k groups are derived from the same population. The alternative hypothesis claims that at least two of the k groups are not derived from the same population.
Step 2: Compute the test statistic, a chi-square value. This value is computed as follows:
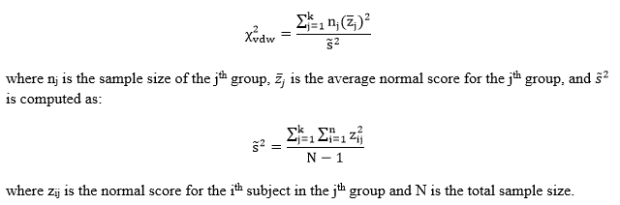
Step 3: Obtain the p-value associated with the calculated chi-square statistic. The p-value indicates the probability of observing a chi-square value equal to or larger than the observed chi-sqaure value from the sample under the assumption that the null hypothesis is true. The degrees of freedom for this test are k – 1.
Step 4: Determine the conclusion. If the p-value is larger than the prespecified α-level, fail to reject the null hypothesis (that is, retain the claim that the k groups are derived from the same population). If the p-value is smaller than the prespecified α-level, reject the null hypothesis in favor of the alternative.
Example
The example for this test is the same as the one from last week. Looking at my songs that are rated five stars, I wanted to see if the electronic, alternative, and “other genre” songs were derived from the same population. Here, n = 50 and let α = 0.05.
H0: the k = 3 groups are derived from the same population.
Ha: at least two of the k = 3 groups are not derived from the same population.
The values necessary for this test are displayed in the following tables. The explanations follow.


The first column just contains the raw data values.
The second column contains the ranks. To obtain the ranks of the songs, I did the following steps:
First, I sorted the songs by playcount.
Second, I ranked the songs from 1 to 50 based on their playcount, with 1 corresponding to the song with the highest playcount and 50 corresponding to the song with the lowest playcount. Note that I could have done this the opposite way (1 corresponding to the least-played song and 50 corresponding to the most-played song; the resulting chi-square value would be the same).
Third, I adjusted the ranks for ties. Where there were ties in the playcount, I summed the ranks that were taken by the ties and then divided that value by the number of tied values. I then replaced the original ranks with the newly calculated value.
The third column contains the normal score values for each rank-order. To obtain these values, I did the following:
First, I took each individual rank and divided it by N + 1 = 51. This gave me a proportion that could be conceptualized as the percentile for that score (if multiplied by 100).
Second, I found the standard normal score (z-score) that corresponded to that percentile and input that as the entry for column 3.
Computations
The following three values are the sums of the normal scores for each genre:
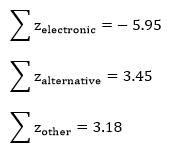
And these three values are the average normal scores for each genre:

Here, our computed p-value is greater than our α-level, which leads us to fail to reject the null hypothesis, which is the claim that the three genre groups are derived from the same population.
Example in R
No example in R this week, as this is probably easier to do by hand than using R!

