Let’s keep going with measures of correlation and talk about Goodman and Kruskal’s gamma today!
When Would You Use It?
Goodman and Kruskal’s gamma is a nonparametric test used to determine, in the population represented by a sample, if the correlation between subjects’ scores on two variables is some value other than zero.
What Type of Data?
Goodman and Kruskal’s gamma requires both variables to be ordinal data.
Test Assumptions
No assumptions listed.
Test Process
Step 1: Formulate the null and alternative hypotheses. The null hypothesis claims that in the population, the correlation between the scores on variable X and variable Y is equal to zero. The alternative hypothesis claims otherwise (that the correlation is less than, greater than, or simply not equal to zero).
Step 2: Compute the test statistic, a z-value. To do so, Goodman and Kruskal’s gamma, G, must be computed first. The following steps must be employed:
- Arrange the data into an ordered r x c contingency table, with r representing the number of levels of the X variable and c representing the number of levels in the Y variable. The first row represents the category that is lowest in magnitude on the X variable and the first column represents the category that is lowest in magnitude on the Y variable. Within each cell of the table is the number of subjects whose categorization on the X and Y variables corresponds to the row and column of the specified cell.
- Calculate nc, the number of pairs of subjects who are concordant with respect to the ordering of their scores on the two variables. This is done as follows, starting at the upper left-hand corner of the table: for each cell, determine the frequency of that cell, then multiply that frequency by the sum of all the frequencies of all cells that fall both below it and to the right of it. The sum of these products is nc.
- Calculate nd, the number of pairs of subjects who are discordant with respect to the ordering of their scores on the two variables. This is done as follows, starting at the upper right-hand corner of the table: for each cell, determine the frequency of that cell, then multiply that frequency by the sum of all the frequencies of all cells that fall both below it and to the left of it. The sum of these products is nd.
- Compute G as follows:
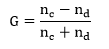
The test statistic itself is calculated as:

Where N is the total number of subjects whose scores are recorded in the contingency table.
Step 3: Obtain the p-value associated with the calculated z-score. The p-value indicates the probability of observing a correlation as extreme or more extreme than the observed sample correlation, under the assumption that the null hypothesis is true.
Step 4: Determine the conclusion. If the p-value is larger than the prespecified α-level, fail to reject the null hypothesis (that is, retain the claim that the correlation in the population is zero). If the p-value is smaller than the prespecified α-level, reject the null hypothesis in favor of the alternative.
Example
Let’s see if there’s a relationship between stars (3, 4, or 5) and what I consider to be my favorite four genres: electronic, pop, alternative, and rock (in that order). Let X be the song’s genre and let Y be the number of stars received by the song. The following is an ordered contingency table of a sample of 400 songs (100 of each genre).

I suspect a positive correlation between ranked favorite genres and stars. Here, n = 400 and let α = 0.05.
H0: γ = 0
Ha: γ > 0
The calculations for nc and nd:

And G and the test statistic:

Since our calculated p-value is smaller than our α-level, we reject H0 and conclude that the correlation in the population is significantly greater than zero.

