Today we’re going back to parametric testing with the between-subjects factorial analysis of variance!
When Would You Use It?
The between-subjects factorial analysis of variance is a parametric test used in cases where a researcher has a factorial design with two* factors, A and B, and is interested in the following:
- In terms of factor A, in the set of p independent samples (p ≥ 2), do at least two of the samples represent populations with different mean values?
- In terms of factor B, in the set of q independent samples (q ≥ 2), do at least two of the samples represent populations with different mean values?
- Is there a significant interaction between the two factors?
What Type of Data?
The between-subjects factorial analysis of variance requires interval or ratio data.
Test Assumptions
- Each sample of subjects has been randomly chosen from the population it represents.
- For each sample, the distribution of the data in the underlying population is normal.
- The variances of the k underlying populations are equal (homogeneity of variances).
Test Process
Step 1: Formulate the null and alternative hypotheses. For factor A, the null hypothesis is the claim mean of the population levels are equal. The alternative hypothesis claims otherwise. For factor B, the null hypothesis is the claim mean of the population levels are equal. The alternative hypothesis claims otherwise. For the interaction, the null hypothesis claims that there is no interaction between factor A and factor B. The alternative claims otherwise.
Step 2: Compute the test statistics for the three hypothesis. To do so, we must find SSA, SSB, and SSAB. First, find the following values:

Then, find the SS values as follows:
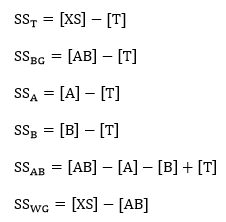
Then find the MS values:

Finally, compute the three test statistics, F-values, for factor A, factor B, and the interaction.

Step 3: Obtain the p-value associated with the calculated F statisticS. The p-value indicates the probability of the ratio of the MSA, MSB, or MSAB to MSWG equal to or larger than the observed ratio in the F statistics, under the assumption that the null hypotheses are true.
Step 4: Determine the conclusion. If the p-value is larger than the prespecified α-level (or the calculated F statistic is larger than the critical F value), fail to reject the null hypothesis (that is, retain the claim that the population means are all equal). If the p-value is smaller than the prespecified α-level, reject the null hypothesis in favor of the alternative.
Example
Today’s example looks at my 2015 music data again! I want to see if a) the mean play count is different for those of my songs that are “favorites” (3+ stars) or non-favorites; b) the mean play count is different for any of four genres of interest (alternative, electronic, pop, rock); c) if there is an interaction between these two factors, genre and favorite status. Here, n = 400 and let α = 0.05.
H0: µfavorite = µnofavorite
Ha: the means are different
H0: µalternative = µelectronic = µpop = µrock
Ha: at least one pair of means are different
H0: there is no interaction between favorite status and genre
Ha: there is an interaction between favorite status and genre
Computations:



Since all of these p-values are smaller than our α-level of 0.05, we would reject the null hypothesis in all three cases.
Example in R
x=read.table('clipboard', header=T)
attach(x)
fit=aov(playcount~favorite+genre+favorite:genre)
summary(fit)
Df Sum Sq Mean Sq F value Pr(>F)
favorite 1 9053 9053 30.587 5.84e-08 ***
genre 3 4333 1444 4.880 0.002419 **
favorite:genre 3 5454 1818 6.143 0.000433 ***
Residuals 392 116016 296
*This test can be done with more factors, but for now, let’s just stick with two.

