We’re back to parametric tests this week with the single-factor between-subjects analysis of variance (ANOVA)!
When Would You Use It?
The single-factor between-subjects ANOVA is a parametric tests used to determine if, in a set of k (k ≥ 2) independent samples, at least two of the samples represent populations with different mean values.
What Type of Data?
The single-factor between-subjects ANOVA requires interval or ratio data.
Test Assumptions
- Each sample of subjects has been randomly chosen from the population it represents.
- For each sample, the distribution of the data in the underlying population is normal.
- The variances of the k underlying populations are equal (homogeneity of variances).
Test Process
Step 1: Formulate the null and alternative hypotheses. The null hypothesis claims that the k population means are equal. The alternative hypothesis claims that at least two of the k population means are different.
Step 2: Compute the test statistic, an F-value. To do so, calculate the following sums of squares values for between-groups (SSB) and within-groups (SSW):
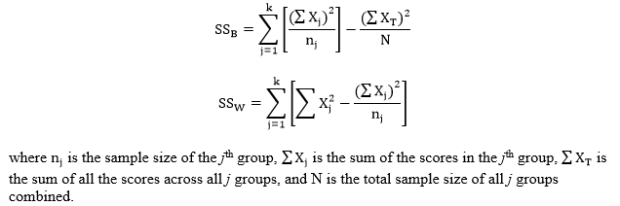
Then compute the mean squared difference scores for between-groups (MSG) and within-groups (MSE):

Finally, compute the F statistic by calculating the ratio:
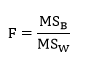
Step 3: Obtain the p-value associated with the calculated F statistic. The p-value indicates the probability of a ratio of MSB to MSW equal to or larger than the observed ratio in the F statistic, under the assumption that the null hypothesis is true. Unless you have software, it probably isn’t possible to calculate the exact p-value of your F statistic. Instead, you can use an F table (such as this one) to obtain the critical F value for a prespecified α-level. To use this table, first determine the α-level. Find the degrees of freedom for the numerator (or MSB; the df are explained below) and locate the corresponding column on the table. Then find the degrees of freedom for the denominator (or MSE; the df are explained below) and locate the corresponding set of rows on the table. Find the row specific to your α-level. The value at the intersection of the row and column is your critical F value.
Step 4: Determine the conclusion. If the p-value is larger than the prespecified α-level (or the calculated F statistic is larger than the critical F value), fail to reject the null hypothesis (that is, retain the claim that the population means are all equal). If the p-value is smaller than the prespecified α-level, reject the null hypothesis in favor of the alternative.
Example
The example I want to look at today comes from a previous semester’s STAT 217 grades. This particular section of 217 had four labs associated with it. I wanted to determine if the average final grade was different for any one lab compared to the others. Here, n = 109 and let α = 0.05.
H0: µlab1 = µlab2 = µlab3 = µlab4
Ha: at least one pair of means are different
Computations:

For this case, the critical F value, as obtained by the table, is 2.70. Since the computed F value is smaller than the critical F value, we fail to reject H0 and conclude that the average final grade is equal across all four labs.
Example in R
x=read.table('clipboard', header=T)
attach(x)
summary(fit)
Df Sum Sq Mean Sq F value Pr(>F)
lab 3 1319 439.5 2.036 0.113
Residuals 105 22670 215.9
R will give you the exact p-value of your F statistic; in this case, p-value = 0.113.

