What’s up, y’all? Today we’re going to talk about the chi-square test for homogeneity!
When Would You Use It?
The chi-square test for homogeneity is a nonparametric test used to determine whether or not r independent samples, categorized on a single dimension, are homogeneous with respect to the proportion of observations in each of the c categories.
What Type of Data?
The chi-square test for homogeneity requires categorical or nominal data.
Test Assumptions
- The data represent a random sample of independent observations.
- The expected frequency of each cell in the contingency table is at least 5.
Test Process
Step 1: Formulate the null and alternative hypotheses. The data appropriate for this type of test is usually summarized in an r x c table, where r is the number of rows of the table and c is the number of columns of the table (see the example below to get a better understanding of this). The null hypothesis claims that the in the population from which the sample was drawn, the observed frequency of each cell in the table is equal to the respective expected frequencies of each cell in the table. The alternative hypothesis claims that for at least one cell, the observed and expected frequencies are different.
Step 2: Compute the test statistic. The test statistic here, unsurprisingly, a chi-square value. To compute this value, use the following equation:

Eij, the expected cell count for the ijth cell, is calculated as follows:
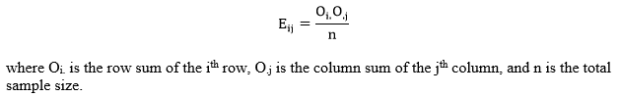
Step 3: Obtain the critical value. The critical value can be obtained using a chi-square table (such as this one here). Find the column corresponding to your specified alpha-level, then find the row corresponding to your degrees of freedom. The degrees of freedom is calculated as df = (r – 1)(c – 1), where r is the number of rows in the table and c is the number of columns in the table. Compare your obtained chi-square value to the value at the intersection of your selected alpha-level and degrees of freedom.
Step 4: Determine the conclusion. If your test statistic is equal to or greater than the table value, reject the null hypothesis. If your test statistic is smaller than the table value, fail to reject the null (that is, claim that the observed cell frequencies match those of the expected cell frequencies).
Example
The example for this test comes from Amazon. Specifically, I want to see if the number of 4+ star ratings was homogeneous across the six different price ranges for laptop computers. I chose a random sample of n = 15 from each of the six price ranges and determined how many of the 15 laptops selected had four or more stars for their average review. The observed counts are in the following table:
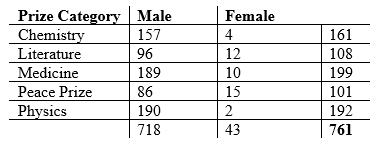
Set α = 0.05.
H0: The proportion of 4+ star ratings is homogeneous across all price ranges
Ha: The proportion of 4+ star ratings is not homogeneous across all price ranges
The expected cell counts, as calculated by the Eij formula above, are displayed in the following table:
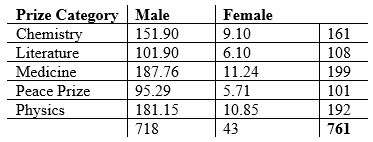
Calculating the chi-square value gives us:

The degrees of freedom for this test is df = (6 – 1)(2 – 1) = 5, which gives us a critical chi-square value of 11.070 by the table. Since our calculated chi-square value, 3.54, is smaller than the table value, this suggests that we fail to reject the null and claim that the proportion of 4+ star ratings is the same for each price category.

