Today we’ll be discussing another commonly used statistical test—one that is highly related to last week’s test: the single-sample t test!
When Would You Use It?
The single-sample t test is a parametric test used in a single sample situation to determine if the sample originates from a population with a specific mean µ. This test is used when the population standard deviation, σ, is not known (it must be estimated with the sample standard deviation, s).
What Type of Data?
The single-sample t test requires interval or ratio data.
Test Assumptions
- The sample is a simple random sample from the population of interest.
- The distribution underlying the data is normal.
Test Process
Step 1: Formulate the null and alternative hypotheses. The null hypothesis claims that the mean in the population is equal to a specific value; the alternative hypothesis claims otherwise (the population mean is greater than, less than, or not equal to the value specified in the null hypothesis.
Step 2: Compute the t-score. The t-score is computed as follows:
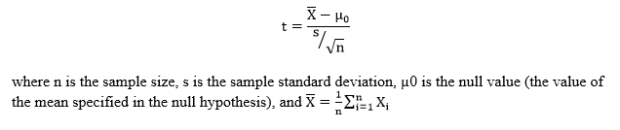
Step 3: Obtain the p-value associated with the calculated t-score. The p-value indicates the probability of observing a sample mean as extreme or more extreme than the observed sample mean, under the assumption that the null hypothesis is true.
Step 4: Determine the conclusion. If the p-value is larger than the prespecified α-level, fail to reject the null hypothesis (that is, retain the claim that the mean in the population is equal to the value specified in the null hypothesis). If the p-value is smaller than the prespecified α-level, reject the null hypothesis in favor of the alternative.
Example
The data for this example are the recorded mileages of my n = 306 walks from 2015. Mileage is recorded to the second decimal place. Since there is no real way I can determine what the population standard deviation should be, I will estimate it with the sample standard deviation, and thus must use a t test for a test of the mean value. I’m going to guess that my average walk is greater than 7 miles, ‘cause I honestly can’t remember what the actual average was, but I’m pretty sure it was more than 7. Set α = 0.05.
H0: µ = 7 miles
Ha: µ > 7 miles
The sample mean is calculated to be 8.246 and the sample standard deviation is calculated to be 4.429
Computations:

Since our p-value is much smaller than our alpha-level, we reject H0 and claim that the population mean is greater than 7 miles.
Example in R
dat=read.table('clipboard',header=T) #'dat' is the name of the imported raw data
mu = 7
s = sd(dat)
n = 306
xbar = mean(dat)
t = (xbar-mu)/(s/sqrt(n)) #t-score
pval = (1-pt(t, n-1))*2 #p-value
#n-1 is the degrees of freedom

